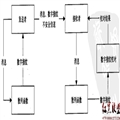
1 重要结论
J2SE 5.0 用的是Unicode 4.0
J2SE 6.0 用的也是Unicode 4.0
Java
编程语言用16位的
编码代表文本。使用UTF-16编码.
一个 char 表示一个 UTF-16 编码单元
并不是一个char代表一个字符,因为一个增补字符需要2个char来代表
2 准备知识:
2.1 gbk编码
字符“我”的gbk编码: ced2
可以到GBK编码表去验证
http://www.microsoft.com/globaldev/reference/dbcs/936.mspx
2.2 utf16编码
字符“我”的utf-16编码:编码,6211
可以参考从unicode官方网站上下载下来的《U4E00.pdf》确认此事。
其实U4E00.pdf里面查到的只是代码点。
而utf-16编码,对于普通字符来说(即不是增补字符),和代码点是一致的。
2.3 utf-8编码
字符“我”的utf-8编码: e6 88 91
可以靠下面代码来验证:
import java.io.UnsupportedEncodingException;
public class Test {
public static void main(String[] args) throws UnsupportedEncodingException {
String s = "我";
byte[] bytes = s.getBytes("utf-8");
for (int i = 0; i < bytes.length; i++) {
System.out.println(Integer.toHexString(bytes[i]));
}
}
}
3 场景1
response.setContentType("text/html;charset=GBK"); 没写
request.setCharacterEncoding("GBK"); 没写
server.xml?Connector?URIEncoding="GBK" 没设置
OneParam.java
import javax.servlet.*;
import javax.servlet.http.*;
import java.io.*;
public class OneParam extends Http
Servlet {
private static final long serialVersionUID = 1L;
@Override
protected void doGet(HttpServletRequest request,
HttpServletResponse response) throws ServletException, IOException {
PrintWriter out = response.getWriter();
String s = "我";
System.out.println(s);
out.println(s);
}
}
web.xml
<servlet>
<servlet-name>OneParam</servlet-name>
<servlet-class>OneParam</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>OneParam</servlet-name>
<url-pattern>/servlet/OneParam</url-pattern>
</servlet-mapping>
访问这个地址:http://127.0.0.1/my/servlet/OneParam
观察到的现象是:页面本身有乱码。
首先,编译得到的字节码文件中,这个字符被存储为utf-8编码形式。
可以用ultraedit软件,打开class文件,切换到16进制来验证。
当执行这句话时候,
String s = "我";
先说=右边,要在方法区创建一个字符串对象出来。
jvm在读入字节码的时候,当然知道这个字符串在字节码中是默认存成utf-8编码的。
unicode代码点和uft-8编码之间的对应关系是固定的。即:
UCS-2 (UCS-4) 位序列 第一字节 第二字节 第三字节 第四字节
U+0000 .. U+007F 00000000-0xxxxxxx 0xxxxxxx
U+0080 .. U+07FF 00000xxx-xxyyyyyy 110xxxxx 10yyyyyy
U+0800 .. U+FFFF xxxxyyyy-yyzzzzzz 1110xxxx 10yyyyyy 10zzzzzz
U+10000..U+1FFFFF 00000000-000wwwxx-
xxxxyyyy-yyzzzzzzz 11110www 10xxxxxx 10yyyyyy 10zzzzzz
通过固定的转换关系,jvm能够得到正确的unicode代码点(6211)。
对于普通字符,unicode代码点和utf-16编码是一致的。(增补字符除外)
即会在
内存里面表示为6211。
局部变量s指向了这个对象。
s?62 11。
由于内存里面记录了“我”这个字符的正确的uft-16编码。
当然我们执行下面这句话能够得到正确的中文。
System.out.println(s);
接下来是:
out.println(s);
把这个字符串传到客户端浏览器。
JVM这里可不是把内存里面的内容不做任何转换直接传到浏览器。JVM必须以某种编码形式来传递这个字符串。因为没有指明到底以什么编码来传递。所以默认是iso8859-1。
所以tomcat帮忙调用s.getBytes("iso8859-1"),
因为在iso8859-1编码表里面,没有“我”这个字符。我们会得到
错误的iso8859-1编码。
这会得到1个字节,如果用10进制标识为63,如果用16进制标识为3f,tomcat然后把这1个字节传给客户端。
下面代码演示s.getBytes("iso8859-1")会得到错误的编码:
import java.io.UnsupportedEncodingException;
public class Test {
public static void main(String[] args) throws UnsupportedEncodingException {
String s = "我";
byte[] bytes = s.getBytes("iso8859-1");
for (int i = 0; i < bytes.length; i++) {
System.out.println(Integer.toHexString(bytes[i]));
//System.out.println(bytes[i]);
}
}
}
客户端只接收到这个3f,我们可以靠下面的程序验证这一点:
Test
HTTP.java
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.net.Socket;
public class TestHTTP {
public static void main(String[] args) throws Exception {
Socket s = new Socket("127.0.0.1", 80);
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(s
.getOutputStream()));
bw.write("GET /my/servlet/OneParam HTTP/1.1");
bw.newLine();
bw.write("Host: 127.0.0.1:80");
bw.newLine();
bw.write("Content-Type: text/html");
bw.newLine();
bw.newLine();
bw.flush();
// BufferedReader br = new BufferedReader(new InputStreamReader(s
// .getInputStream()));
// String str = null;
// while ((str = br.readLine()) != null) {
// System.out.println(str);
// }
InputStream br = s.getInputStream();
int i = 0;
while ((i = br.read()) != -1) {
System.out.print(" " + i);
}
bw.close();
br.close();
s.close();
}
}
72 84 84 80 47 49 46 49 32 50 48 48 32 79 75 13 10 83 101 114 118 101 114 58 32 65 112 97 99 104 101 45 67 111 121 111 116 101 47 49 46 49 13 10 67 111 110 116 101 110 116 45 76 101 110 103 116 104 58 32 51 13 10 68 97 116 101 58 32 84 104 117 44 32 50 51 32 65 112 114 32 50 48 48 57 32 48 49 58 49 55 58 49 52 32 71 77 84 13 10 13 10 63 13 10
看到没?倒数第3个字节是63。如果用16进制标识为3f
ascii字符集里规定,3f是“?”这个字符
可以到这个地址来验证:http://www.jimprice.com/jim-asc.shtml
你的浏览器菜单,察看?编码这一项,可能自动设置为gb2312.即使这样。浏览器依然会按照gbk来显示内容。
gbk编码表,和ascii编码是兼容的。所以会显示成1个?
可以到这里来验证。
http://msdn.microsoft.com/zh-cn/goglobal/cc305153(en-us).aspx
即使你通过浏览器菜单?察看?编码这一项设置为其它的编码。比如:iso8859-1
看到的也是?,因为iso8859-1和ascii编码也是兼容的。
4 附
gbk编码
- 尚学堂.张志宇.乱码分析_02_servlet乱码.rar (32.2 KB)
- 下载次数: 15