本文主要讲述NoSQL在Flash设备上的可以选择的其中一种优化策略,并粗略提了一下SSD设备的特性。
对Flash设备的性能优化,微软曾经做过一份paper,但是里面很多东西比较局限:比如paper中将SSD作为了写入的buffer,而众所周知,写性能不会是任何一款NoSQL的瓶颈;比如SSD的索引采用了Hash的数据结构,这样在进行cache evict的时候,粒度的控制也很有问题。本文对其进行了改进,罗列如下:
SSD对于传统硬盘的优势在于它没有机械装置,介质也由磁介质变为了电介质,因此它具备直接按地址读取数据的能力,没有了寻道时间,这也是为什么SSD的IOPS可以达到数万的原因。
而SSD的写操作比较特殊,其最小写入单元是4K,当写入空白位置的时候可以直接写入,但是当需要改写某个单元时,则需要一个额外的擦出操作,擦除的操作一般是128个page,每个擦出的单元称为一个块。
因为SSD的存储单元寿命有限,因此,当某个特定的部位被频繁擦写,不仅会造成性能问题,而且使得SSD寿命大幅降低,所以SSD做了Wear Leveling,即损耗均衡算法。这样,当需要改写某个page时,并不写入原有位置,而是读取现有块,合并需要改写的数据,然后一起写入新的空闲块,原有的块被标记为invalid,等待被擦除回收。这样做的好处在于,一是不会反复擦写同一个block,二是写入的速度会比较快(省略了擦除的动作)。
因为SSD的erase-before-write的特性,所以就出现了一个写入放大的概念,比如你想改写4K的数据,必须首先将整个擦除块(512KB)中的数据读出到缓存中,改写后,将整个块一起写入,这时你实际写入了512KB的数据,写入放大系数是128。写入放大最好的情况是1,就是不存在放大的情况。
综合SSD的特性,我们需要做到以下两点来合理使用SSD并且提高其使用寿命:
?
1.?尽量避免随机写。由于损害均衡算法的存在,随机写特定page将造成写入放大。
2.?避免每次写入过少的数据。如果每次写入的数据不足SSD的一个page大,那么当前写入的数据将导致该page有浪费,并且接下来对该文件逻辑上的append将导致,之前写的不足一个page的数据被读取出来,并合并到新的page中去。
3.?不要使用完全部的空间。SSD的损耗均衡算法虽然一定程度上减少了对特定部位的频繁擦写,但是如果空间不够,这个还是很难避免,因此,最好预留至少50%的空间。
可以看到,不得不说,绝大部分的NoSQL产品都做到了上述两个特性。因此,在新型存储设备上的尝试将是NoSQL时代的主题。
虽然当前SSD相比内存便宜了很多,但目前SSD每存储单元在价格上仍然比普通硬盘要贵很多,因此,在这个过渡时期,普遍的想法是把SSD当做二级Cache。像Flashcache这样利用Linux Device Mapper,将SSD等设备当做Write Back block cache。关于其详细介绍,这里就不多说了,可以去https://github.com/facebook/flashcache 看看官方的介绍。这里讲述另外一种可能比较简单易实现的方式。
根据上面描述的SSD的性能特点,可以采用下面的设计:
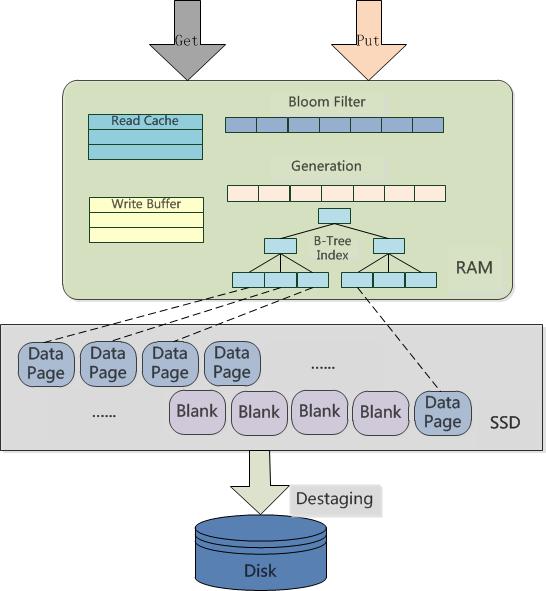
?
上图是逻辑上的结构,物理的实现已经把很多东西都合并了,比如读cache和写buffer,以及SSD的索引B-tree,都可以进行合并成为一颗B-tree(Berkeley Db的方式),另外,我需要强调的一点是,这里的SSD索引使用了B-Tree,相比于Hash是为了提供更粗粒度的SSD Cache失效机制,这一点的原因在上面的SSD特性中已经讲过了,下面讲述get以及set操作的流程。
首先,逻辑上先查询内存中的Read Cache,如果不存在,则查询Write Buffer,然后是SSD Cache的B-Tree Index,然后是Bloom Filter确认key的确在硬盘存在,最后查询到硬盘。
?? ? ?插入的时候,先写到write buffer里面,当buffer到达一个临界值的时候将其刷到SSD上,当SSD到达一个临界值的时候,将其踢出并移到硬盘,当然整个过程Bloom Filter也要保持一致。
?
?????caozuo.html" target="_blank">删除操作首先检查内存中的各buffer和cache有没有该值,如果有,直接在内存中删除其父节点对它的引用,随后直接返回;如果没有,那么先查看Bloom Filter是否该key存在,如果存在则去硬盘上删掉。
?????
这里需要强调的是,删除操作只是一个标记删除,物理文件上的删除会有后台线程定时扫描,这样能够保证每次SSD的擦除操作能更加有效。
???????? 既然SSD做为了二级Cache,那么其必然存在一个evict操作,evict操作的凭据是每个节点的generation,generation会在每次节点被访问的时候+1,这里的+1是一个全局的+1,即整颗树维护一个long型的generation,A节点被访问一次则其generation为1,那么过一会B节点被访问那么generation为2,以此类推。
???????? Evict的时候将较小的generation的节点删除,将其踢到硬盘,这里需要注意,这里的节点我指的是非页节点,因此,一般情况下,每次evict至少有默认128个叶节点被踢出,即使这128个节点物理上的位置不连续,由于我们有后台的clean线程(参加海量数据存储之Key-value存储简介的过期数据清理一章)的参与,因此,我们总能保证,每次SSD的擦除操作都是连续并且是大块的。
???????? 最后,很显然,这样的设计L1 Cache、L2 Cache以及Disk组成了一套完整的数据,因此,在掉电的时候,SSD的cache无需失效,当然,前提是由于我们的系统有Write-ahead-log保证了内存中的数据掉电不丢失。
http://www.hellodba.net/2010/10/ssd-database-2.html
http://research.microsoft.com/apps/pubs/default.aspx?id=131572