hash碰撞冲突:
? ? ? ? 我们都知道hashCode()的方法是为了产生不同的hash值,但是当两个对象的hash一样时,就发生了碰撞冲突;
解决方法:
? ? ? ? ?我们 常用的解决方法有四种:
? ? ? ? ?①:开放地址法;
? ? ? ? ?②:再hash的方法;
? ? ? ? ?③:拉链法;
? ? ? ? ?④:建立公共溢出区法;
?
开放地址法:
? ? ? ?
class="java" name="code">基本思想:当发生地址冲突的时候,按照某种方法继续探测哈希表中的其他存储单元,直到找到空位置为止; 所用公式 Hi(key) = [H(key) + di]mod m;其中i = 1、2、3.....k(k<m-1),H(key)为关键字key的直接hash地址;M为hash表的长度; di为再次探测时的地址增量;根据di的不同取法,有不同的称呼; 线性探测再散列:di = 1、2、3、4....k (k<m-1) 二次探测再散列:di = 1^2,-1^2,2^2,-2^2.....k^2,-k^2 (k<=m/2) 伪随机再散列:di = 伪随机数
?测试代码如下:
?
?
public class Test1 {
//线性探测再散列
public static int[] m1(int[] arr){
if (arr==null || arr.length == 0){
return null;
}
int[] arr1 = new int[arr.length];
for (int i = 0;i<arr.length;i++){
int p = arr[i]%(arr1.length);
if (arr1[p]==0){
arr1[p] = arr[i];
}else {
for (int j = 1 ; j<5;j++){
int p1 = (p+j)%(arr1.length);
if (arr1[p1]==0){
arr1[p1] = arr[i];
}
}
}
}
return arr1;
}
//二次探测再散列
public static int[] m2(int[] arr){
if (arr==null || arr.length == 0){
return null;
}
int[] arr1 = new int[arr.length];
for (int i = 0;i<arr.length;i++){
int p = arr[i]%(arr1.length);
if (arr1[p]==0){
arr1[p] = arr[i];
}else {
for (int j = 1 ; j <= 5/2;j++){
int p1 = (p+j*j)%(arr1.length);
int p2 = (p-j*j)%(arr1.length);
if (p1<=arr.length && arr1[p1]==0){
arr1[p1] = arr[i];
}
if (p2>=0 && arr1[p2]==0){
arr1[p2] = arr[i];
}
}
}
}
return arr1;
}
//伪随机再散列
public static int[] m3(int[] arr){
if (arr==null || arr.length==0){
return null;
}
int[] arr1 = new int[arr.length];
for (int i = 0;i<arr.length;i++){
int p = arr[i]%(arr1.length);
if (arr1[p]==0){
arr1[p] = arr[i];
}else {
while (true){
int p1 = (int) ((p+arr.length*Math.random())%(arr1.length));
if (p1<=arr.length-1 && arr1[p1]==0){
arr1[p1] = arr[i];
break;
}
}
}
}
return arr1;
}
//数组输出函数
public static void arrayPrint(int[] arr){
if (arr == null){
System.out.println("数组为null");
}else {
for (int k = 0 ;k<arr.length;k++){
System.out.print(arr[k]+" ");
}
System.out.println();
}
}
public static void main(String[] args){
int[] arr = {13,45,34,56,33};
int[] arr1 = m1(arr);
int[] arr2 = m2(arr);
int[] arr3 = m3(arr);
arrayPrint(arr2);
arrayPrint(arr1);
arrayPrint(arr3);
}
}
?再hash的方法:
?
? ? ? ?当发生冲突时,使用第二个、第三个、哈希函数计算地址,直到无冲突时。缺点:计算时间增加。
? ? ? ?比如上面第一次按照姓首字母进行哈希,如果产生冲突可以按照姓字母首字母第二位进行哈希,再冲突,第三位,直到不冲突为止;
?
拉链法:
在HashMap中 就是使用拉链法 来解决hash冲突的问题的;
将所有关键字为同义词的记录存储在同一线性链表中。如下:
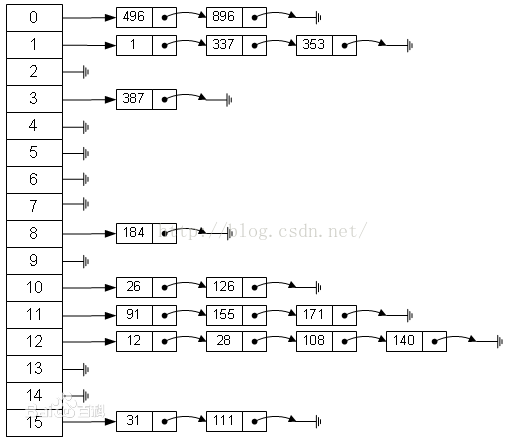
?
建立公共溢出区:
?
? ? 建立公共溢出区的基本思想是:假设哈希函数的值域是[1,m-1],则设向量HashTable[0...m-1]为基本表,每个分量存放一个记录,另外设向量OverTable[0...v]为溢出表,所有关键字和基本表中关键字为同义词的记录,不管它们由哈希函数得到的哈希地址是什么,一旦发生冲突,都填入溢出表。
?
拉链法的优缺点:?来自:
http://blog.csdn.net/zeb_perfect/article/details/52574915
?
?
?