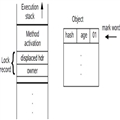
在Java里面所有的类都直接或者间接的继承了java.lang.Object类,Object类里面提供了11个方法,如下:
class="java">
````
1,clone()
2,equals(Object obj)
3,finalize()
4,getClass()
5,hashCode()
6,notify()
7,notifyAll()
8,toString()
9,wait()
10,wait(long timeout)
11,wait(long timeout, int nanos)
````
这里面我们常用的方法有三个:
````
toString()
equals(Object obj)
hashCode()
````
toString方法,相信用过Java的人都不会陌生,默认打印的是:类名@十六进制的hashCode,源码中定义如下:
````
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
````在经过重写后,我们可以打印一个class的所有属性,这样在打印log或调试时比较方便。
下面重点介绍下hashCode和equals方法:
(1)equals方法,在JDK默认的情况下比较的是对象的
内存地址,源码如下:
````
public boolean equals(Object obj) {
return (this == obj);
}
````
(2)hashcode方法,默认情况下返回的是一个唯一的整数,代表该实例的内存地址,注意这个数字
并不是实际的内存地址,Java是没办法直接获取内存地址的,必须得由C或者C++获取,所以这个方法是用
native修饰的
````
public native int hashCode();
````
由于默认情况下,equals方法比较的是内存地址,而在实际开发中,我们判断两个对象是否相等,一般都是根据对象的属性来判断的,
所以需要重写这个方法,不然的话,是没办法比较的。举例如下:
定义的类如下:
````
public class Hero {
private String id;
private String name;
public Hero() {
}
public Hero(String id, String name) {
this.id = id;
this.name = name;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
````直接比较两个对象,结果是不相等的:
````
`````` Hero h1=new Hero("1","张飞");
Hero h2=new Hero("1","张飞");
//false
System.out.println(h1.equals(h2));
````
因为
他们的内存地址是不同的,所以结果是false,如果我们想要认为他是相等的,那么就需要重写
equals方法:
````
@Override
public boolean equals(Object o) {
if (this == o) return true;//如果内存地址相等,则两个对象必定相等
if (o == null || getClass() != o.getClass()) return false;//如果有一个为null或者class不一样,认为必不相等
Hero hero = (Hero) o;//
if (id != null ? !id.equals(hero.id) : hero.id != null) return false;//比较id,不相等就返回false
return name != null ? name.equals(hero.name) : hero.name == null;//上面的条件通过后比较name,如果相等返回true,不相等返回false
}
````
在重写equals方法后,我们在比较两个对象,
发现就相等了
````
``` Hero h1=new Hero("1","张飞");
Hero h2=new Hero("1","张飞");
//true
System.out.println(h1.equals(h2));
````
接着我们看第二个
例子,将其放入ArrayList中,然后判断是否存在,发现也生效了:
````
` Hero h1=new Hero("1","张飞");
List<Hero> heros=new ArrayList<Hero>();
heros.add(h1);
//true
System.out.println(heros.contains(new Hero("1","张飞")));
````
到目前为止,我们还没有对hashCode进行操作,那么大家可能会有一个疑问,既然都有equals方法比较了,为啥还需要hashCode方法呢? 别着急,继续看下面的例子:
我们都知道在Java里面HashSet类,去无序去重的,下面看一下,只重写equasl方法能不能实现对class的去重:
````
` Hero h1=new Hero("1","张飞");
Hero h2=new Hero("1","张飞");
Set<Hero> heros=new HashSet<Hero>();
heros.add(h1);
heros.add(h2);
//2
System.out.println(heros.size());
//false
System.out.println(heros.contains(new Hero("1","张飞")));
````
从上面的结果看,并没有去重,有的小伙伴会说为啥时string类型的时候就能去重?这是因为Stirng类默认已经重写了equals和hashcode方法,当然所有的基本类型都重写这两个方法了。
接着回到上面的问题,为什么在HashSet中去重失效了呢?
其实,不止是HashSet,在HashMap和Hashtable等等所有使用hash相关的数据结构中,如果使用时不重写hashcode,那么就没法比较对象是否存在。
这其实与HashMap存储原理相关(HashSet底层用的也是HashMap),HashMap在存储时其实是采用了数组+链表的存储结构,数组
中的每一个元素,我们可以
理解成是一个buckets(桶),桶里面的结构是链表,而数据是如何分到各个桶里面其实与hashCode有很大关系,只有hashCode一样的
对象才能被分到一个桶里。存的时候,遍历链表判断是否存在,如果存在就不覆盖,如果不存在就把该元素放在链表的头,把next指向上一次的头,而读取的时候先定位到桶里,然后遍历
链表找到该元素即可。
理解了这些,就明白了为啥上面的例子中,去重失效了。就是因为他们的hashCode不一样,导致被分到不同的桶里面了,自然就没法去重了。
重写hashCode之后,再看结果:
````
@Override
public int hashCode() {
return Integer.parseInt(id);
}
````
````
・ Hero h1=new Hero("1","张飞");
Hero h2=new Hero("1","张飞");
Set<Hero> heros=new HashSet<Hero>();
heros.add(h1);
heros.add(h2);
//1
System.out.println(heros.size());
//true
System.out.println(heros.contains(new Hero("1","张飞")));
````
这下结果就对了。
那么问题来了,为啥需要hashCode? 因为在HashSet中,可以存储大量的元素,如果没有hashCode,那么每次就得全量的比较每一个元素,来判断
是否存在,这样以来效率肯定极低,而有了hashCode之后,只需要找到该数据的链表,然后遍历这个链表的数据即可,这样以来效率
就大大提升。
总结:
(1)如果两个对象相等,那么他们必定有相同的hashcode
(2)如果两个对象的hashcode相等,他们却不一定相等
(3)重写equasl方法时,一定要记得重写hashcode方法,尤其用在hash类的数据结构中。
有什么问题可以扫码关注微信公众号:我是攻城师(woshigcs),在后台留言咨询。 技术债不能欠,健康债更不能欠, 求道之路,与君同行。