服务端,顾名思义就是为用户提供服务的。
停工时间,就是不能向用户提供服务的时间。
高可用,就是系统具有高度可用性,尽量减少停工时间。
停工的原因一般有:
停工的原因,可以理解为灾难,所以系统的高可用性就是容灾,即应对灾难的能力,系统有较好的容灾能力,也就是即使灾难出现,系统依然可以正常工作。
例如:
从范围了说,有可能是一台机器,也有可能是多台机器(机房或者某个区域,例如广东),甚至全部机器(那就没救了..)。
思路就是在多台机器上部署服务,即使一台机器出现问题,其他机器依然可以提供服务。当然,比较可靠的是,多台机器最好在不同的机房,不同的地域,但是对应的成本也会上升。
主服务负责提供服务,从服务负责监测主服务器的心跳。当主服务出现问题,立刻转换为从服务器提供服务。例如Mysql的的的主从架构。
在?台机器上面,运行?个服务,通过负载均衡,把请求分发到不同的机器。当其中一台机器出现问题。系统会自动的切换流量,也就是把请求都导流到其他正常的机器上。
例如:
优化思路:
系统繁忙,请稍后再试。否则,用户会不断重试,让已经负载很高的系统雪上加霜。重试的频率,例如30秒后才能重试,或者没有收到服务端的返回前,不能再次提交请求。也可以在Nginx的层加入限制,同一IP1秒内不能发送多于?个请求,多于的就快速拒绝,防止被攻击。
当我们采用了各种措施来提升系统的容灾能力后,怎么测试我们的措施是否有用呢?
应用一般都是针对上面的机器问题导致的机器层面的灾难,因为业务层面的,一般是在代码开发阶段考虑的。
高可用可以分为两个关键点:
多节点,也就是要部署多个节点,无论其他节点是挂起状态(主从),还是工作昨天(多机多工)。
当有了多节点后,还是不够的,因为当灾难来临的话,如果要人工去切换流量,必然要花费较长时间,所以需要有自动切换流量的机制。
自动切换流量的另一个功能就是,当损坏的节点恢复后,流量又会自动得切回去。
常用的服务端架构,一般是这样: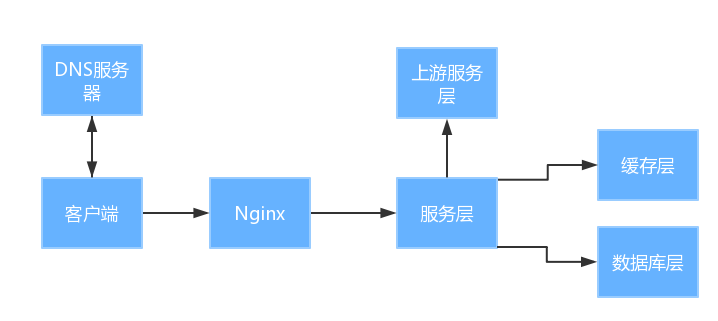
会部署多个Nginx的层,DNS服务器中部署多个IP,这样DNS服务器会把流量均匀地分到多个Nginx的。
缺点是:
本机的主机配置中,可以设置一个域名对应多个IP,设置方法:
192.168.137.130 www.test.com?
192.168.137.133 www.test.com?
主机的解析策略是,先访问第一个IP,如果失败,才会访问第二个IP?
所以没有负载均衡的功能,但是有自动流量切换的功能。
Nginx可以配置多个服务层
。Nginx有监听服务层是否可用的机制(上行),所以可以实现自动切换流量
nginx的配置
class="hljs nginx">upstream gunicorn_pool
{
#server 地址:端口号 weight表示权值,权值越大,被分配的几率越大;max_fails表示在fail_timeout中失败的最大次数,如果达到该次数,就不再导流量到该server
server 192.168.137.130:9098 weight=4 max_fails=2 fail_timeout=30s;
server 192.168.137.133:9098 weight=4 max_fails=2 fail_timeout=30s;
}
server {
listen 80;
server_name 127.0.0.1 www.test.com;
access_log /data/logs/nginx_access.log;
error_log /data/logs/nginx_error.log;
location @gunicorn_proxy {
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
proxy_redirect off;
proxy_pass http://gunicorn_pool;
}
}配置一个上游,gunicorn_pool。里面有两个服务层(130和137)
如果两个服务层都正常,Nginx的的会把流量根据重量值,导流到两个服务器。
同一个请求中,如果nginx的的导流到server1的的,发现返回的是错误响应(例如502),nginx的的会把请求再发送服务器2,相当于重试。这时会记录server1的的的失败次数+1?
如果再fail_timeout时间内,服务器1的失败次数超过max_fails,在fail_timeout时间内,nginx的的就不会再把其他请求导流到Server1上上了。
上面的机制,就可以实现自动的流量切换。当然也有负载均衡的功能,这个就是高并发的范畴了。
常用的缓存有Redis的的和MongoDB中的
Redis的集群
mongo HA
常用的数据库就是Mysql的的了。
配置DNS服务器,一个域名,对应多个知识产权,
缺点是不能实现流量自动切换,例如S1挂了,DNS还是会返回S1的的的iP给客户端,客户端可能要重试几次,才会拿到其他服务器的IP,才能实现连接。
由于TCP是长连接,所以获取IP的请求是很少的,所以可以自己写一个接口,客户端通过接口来获取TCP Server的IP地址。
这样的接口里面就可以做到自动切换流量了。已经挂了,就不会返回A机器的IP了
.TCP Server可以把自己的状态放在Redis,然后接口那边就可以获取TCP Server的状态了
也可以TCP Server提供一个http接口,返回自身的状态,供得到-IP接口那边调用。
?
在互联网公司面试中,架构的底层一定是面试官会问问的问题,针对面试官一般会提到的问题,我录制了一些分布式,微服务,性能优化等技术点底层原理的录像视频,加群619881427可以免费获取这些录像,里面还有些分布式,微服务,性能优化,春天设计时,MyBatis的等源码知识点的录像视频。这些视频都是?找一些资深架构师朋友一起录制出来的,这些视频帮助以下几类程序员:
1.对现在的薪资不满,想要跳槽,却对自己的技术没有信心,不知道如何面对面试官。
3.工作1 - 5年需要提升自己的核心竞争力,但学习没有系统化,不知道自己接下来要学什么才是正确的,踩坑后又不知道找谁,百度后依然不知所以然。
4.工作5 - 10年无法突破技术瓶颈(运用过很多技术,在公司一直写着业务代码,却依然不懂底层实现原理)
如果你现在正处于我上述所说的几个阶段可以加下我的群来学习。而且我也能够提供一些面试指导,职业规划等建议。