# Java进阶之
内存模型介绍
### 前言
不管在什么
编程语言里面,读取和写入都是我们程序最普遍的操作,在单
线程的程序里面我们可能不关注线程的读写问题,但是一旦到多线程的环境下,读和写就会变得非常敏感。Java内存模型实际上是定义了在多线程环境下使用读和写操作结果一致性的问题。这个模型在JDK5中通过
JSR-133议案进行了修订。
### 为什么需要Java内存模型
主要的原因还是在于方便
程序员更加关注业务本身还不是底层细节,对程序员来说
理解操作系统的内存
架构,CPU指令优化,JIT编译器优化是比较困难的一件事。
### 变量的可见性问题
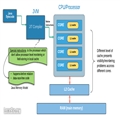
在
多核的服务器时代CPU一般都会拥有多级cache,为了提升其处理性能,比如在上篇文章提到过的L1,L2,L3级cache。这种服务器架构的问题主要在于程序里面的共享变量在横跨多个线程时候的可见性问题。对应到我们写的程序里面就是一个线程写完的变量数据,对于其他线程是否可见。在上面文章中提到过每个线程共享进程的主内存,,同时拥有自己的线程local cache,涉及到变量的读写和可见性问题,其实就是线程的local cache与主内存的数据是否一致的问题。在一个多线程累加同一个变量的程序里面,如果一个线程更新了自己local cache的数据,那么必须在更新完把local cache的数据flush到主内存,否则其他线程读取到的数据就有可能是
错误的,另一方面其他线程知道主内存的数据可能会更新,那么就必须放弃自己local cache的数据,直接从主内存加载最新
版本的数据用来累加,否则就会出现更新结果不正确的情况。(这部分知识现在理解不了,没关系,后面的文章会慢慢梳理。)
### 关于代码指令的重排序问题
为了方便大家理解重排序的概念,我先举个简单的
例子:
```java
public static void main(String []args){
int a=3;
int c=4;
int d=a+c;
System.out.printLn(d);
}
```
上面的代码我们看到a变量是先声明的,c变量是后声明的,但在底层编译,或者JIT优化执行的时候,有可能c变量先被
解析,然后才是a变量,这就叫指令重排序,目的是为了提高执行效率,当然指令重排序是有约定的,不管执行顺序如何变动(底层优化导致),在单线程中,它的最终结果必须是和代码顺序执行的结果是一致的。如上面的程序,a和c的位置可以互换,但是和d的顺序是不能变的,这就是它的约定,这个在后面的文章会解释。
那么什么是指令重排序,通俗点讲就是:
_*你看到的代码顺序,不一定是它的执行顺序。*_
上面说了,重排序只保证在单线程程序中,不影响最终结果的前提下允许JIT或者硬件指令做一些优化,但是在多线程程序中重排序是可能会导致
一些问题的。
### Java内存模型
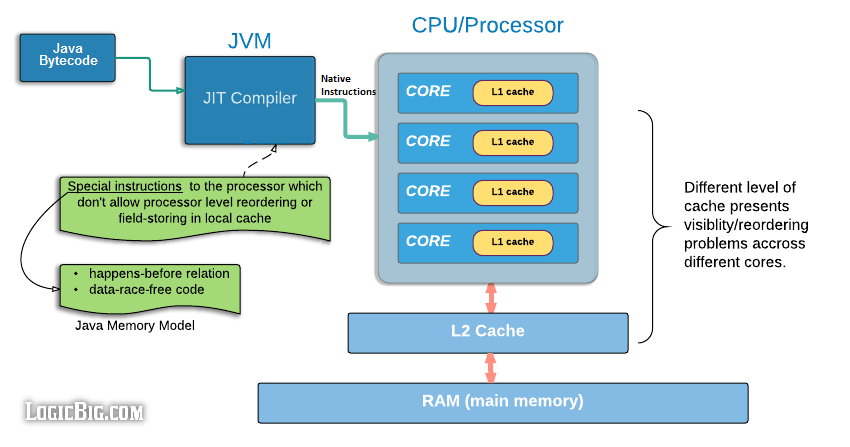
重排序和变量可见性问题是多线程编程里面的主要问题,Java内存模型主要描述了下面两种情况的的处理:
(1)重排序是底层编译器优化的结果,所以在Java内存模型里面有一些 happens-before 规则来约束重排序,比如说如果前后两个变量有依赖关系如上面例子中的a和d那么它是不能被重排序的,否则一旦重排序,是会导致程序逻辑错误。
(2)对于共享数据的写操作,是没法通过happens-before关系来约束的,如上面说到的累加的例子,此时需要通过Java里面锁的机制来避免。
如下图:
### 关于
同步代码块
同步代码块主要完成了两件事情:
(1)对于共享代码在任何时候只保证有一个线程可以操作,这保证了原子性。
(2)lock和unlock操作会触发当前线程flush自己的cache的数据到主内存中,这保证了可见性的问题。
### 关于volatile
关键字
在Java里面用volatie关键字修饰共享变量仅仅只保证可见性,仅仅适用于任何时候只有一个线程更新,多个线程读取的业务。所以如果有超过一个线程以上对变量进行修改,那么必须使用锁机制来处理。
所以请大家记住volatile只保证了可见性,不保证原子性。
### 关于final关键字
在Java里面final关键字修饰的变量,仅仅会被初始化一次,后面是不能修改的。
JIT编译器对final的变量会进行优化,如基本类型String,Int,因为这里不存在修改的问题,那也就没有可见性的问题,所以final修饰基本类型变量在多线程的cache里面的是安全的,不需要和主内存有关联,也就不会有flush或者invalidate的情况。
这也是我们经常说Java里面的String为什么是安全的原因,注意使用final修饰的集合框架如List,Set,Map,虽然内存地址不能变,但是里面的内容是可以变的,这里也是不安全的,这一点需要注意。
这也是为什么有一些函数类型的编程语言如Scala里面严格的提供了不可变的集合框架和可变的集合框架,其目的就是为了更加有利于多线程编程。
最后记住final关键字和volatile关键字是不能修饰同一变量的,在IDE的编译器里面是直接会报错的。
### 总结
如果在阅读之前不了解进程和线程在操作系统里面的关系与特点,我建议你先看看前面的两篇文章再阅读本文。本篇文章主要介绍了Java的内存模型相关内容,如果掌握和熟悉了这些知识,那么对于理解和开发并发编程将是非常有帮助的。
有什么问题可以扫码关注微信公众号:我是攻城师(woshigcs) 路漫漫其修远兮,吾将上下而求索