����һ������CRF����������䷨���������ڲ�CRFģ�͵������������� ˫����Trie��(DoubleArrayTrie)���棬��������ػ���ά�رȺ����㷨������ڡ����������䷨��������ʵ�֡��������ٶȷ���һ�����ﵽ��1262.8655 sent/s
���Ĵ����Ѽ��ɵ�HanLP�п�Դ��Ŀ�У�����hanlp1.7�汾�Ѿ�����
CRF���
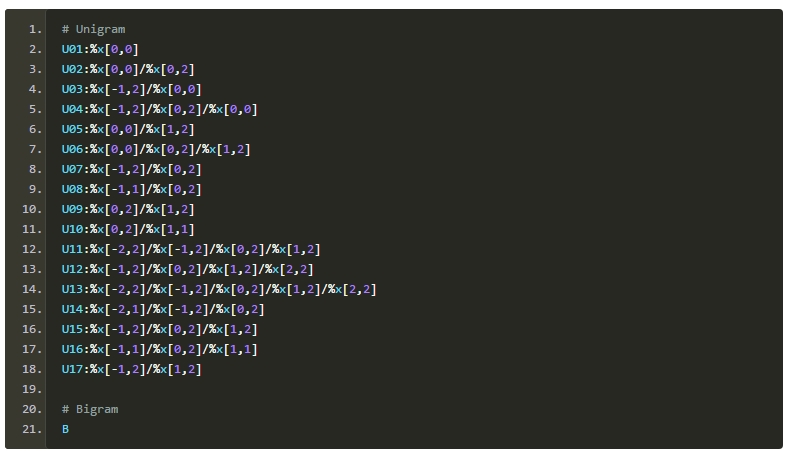
CRF�����б�ע�����г��õ�ģ�ͣ���HMM�����ø������������MEMM���ֿܵ����ƫ�õ����⡣�������о���ʹ�õ�ѵ��������CRF++������CRF++��ʹ���Լ�ģ��ʽ����ġ�CRF++ģ��ʽ˵������
CRFѵ��
���Ͽ�
�롶���������䷨��������ʵ�֡���ͬ�������廪��ѧ���������������ϵ�20000����Ϊѵ������
Ԥ����
�����ϵ��ʵ����������������������㡢�յ㡢��ϵ���ơ��ڱ�CRFģ������ʱ���Ե���ϵ���ƣ������Ŀ�����������ģ�Ͳ�ȫ����
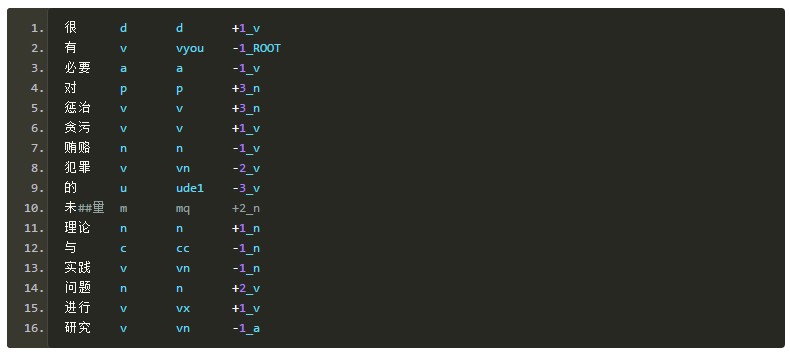
���������ķ�����, ���ǿ���֪������������֮��������ϵ��Ҫ�ж�������: ����;��롣������ǽ�����ǩ����Ϊ�������µ���ʽ:
[ + |- ] dPOS
����, [ + | �C ]��ʾ����, + ��ʾ֧����ھ��е�λ�ó����ڴ����ʵĺ���, �C ��ʾ֧��ʳ����ڴ����ʵ�ǰ��; POS��ʾ֧��ʾ��еĴ������; d��ʾ���롣
����ԭ���⣺

?
ת����
?
����ģ��
?
?
ѵ������
?
1.crf_learn?-f?3?-c?4.0?-p?3?template.txt?train.txt?model?-t
?
�ҵ������������������ܣ����ޣ�ÿ����һ��Ҫ��5���ӣ����ֻ���趨��������Ϊ100������ʹ��ĵ������õ���һ��Ч���dz�����ģ�ͣ���serr�ߴ�50%����ʱֻ���㷨�����á�
����
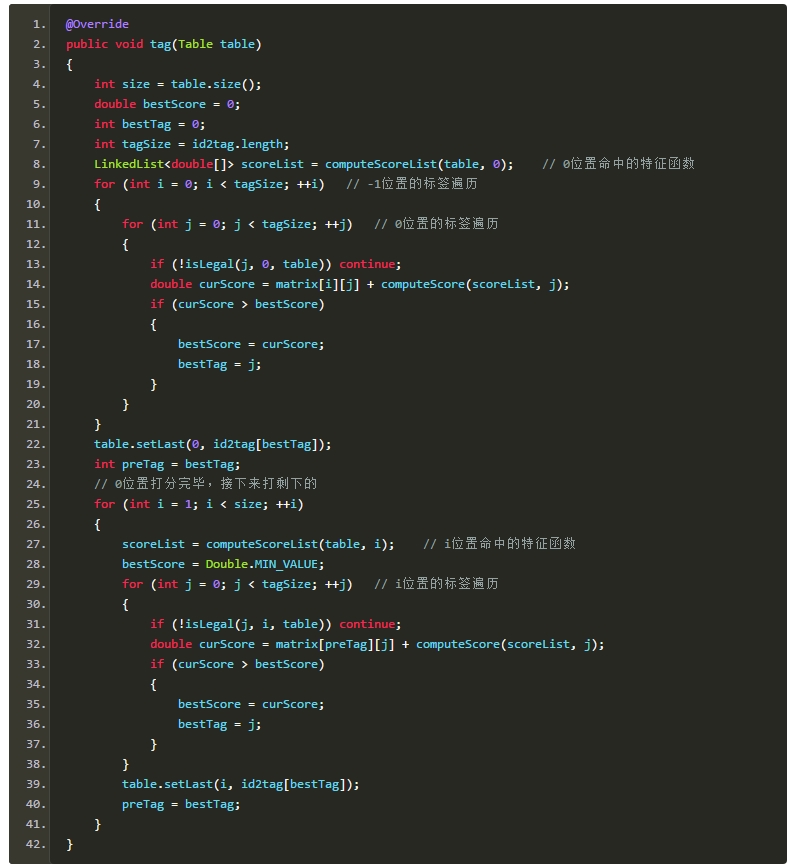
����ά�ر��㷨�ٶ����б�ǩ���ǺϷ��ģ������ڱ�CRFģ���У���ǩ���ܵ����ӵ�Լ�����������һ���ʵı�ǩ��������+nPos�������Ǹ����������κδʵ�[+/-]nPos���ñ�֤���棨��ǰ�棬������Ϊ����ʱ����n������ı�ǩ��Pos�������Ҹ�д��CRF��ά�ر�tag�㷨���������£�
?
?
ע�������
?
?1.if (!isLegal(j, i, table)) continue;
?
��֤�˱�ǩ�ĺϷ��ԡ�
��һ���Ľ����
?

?
��������
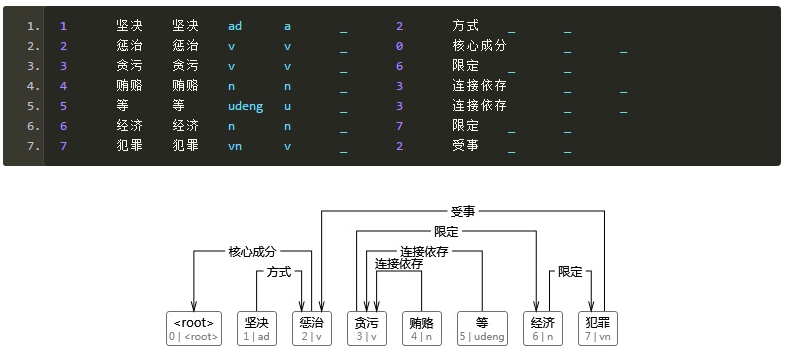
��������Ķ�����Ҫ֪�����������ϵ���������־�������ơ��Ҵ�������ͳ���������ʵĴ������������ϳ��ָ��ʣ����ҳ���Ϊ2gramģ�ͣ��ô�ģ�ͽ�����������˵Ĵ�����������ܵĹ�ϵ���ơ�
���ս��
ת��ΪCoNLL��ʽ�����
?
?
?





 class='magplus' title='����鿴ԭʼ��СͼƬ' />
class='magplus' title='����鿴ԭʼ��СͼƬ' />





