??????? 八月已过半,凉秋也到了,但七月的故事还得继续讲、继续想、继续反思。我们不能否认历史,纵然历史是空白或者黑暗肮脏的。
??????? XML文件到底有多重要,我仍然没有深刻的体会到,也许这需要到更多的实战中去,闻过了血腥才知道战争的可怕。
??????? 需要提前声明的是,JAVA对XML文件的操作有很多种方法,DOM树是最容易理解的一种,但是效率、实用性有待验证。
??????? 代码是冗长的,思路却很简单。封装、解析XML文件主要是用Document类,来获取一个DOM树,然后向树中添加或从树中获取节点。
??????? 测试代码如下。
package com.xml;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.PrintWriter;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.TransformerFactoryConfigurationError;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
/**
* @author wkupaochuan
* @time Aug 16, 2012
* @version V 1.0
*/
public class Blog {
public static void main(String agrs[])
{
createXml();
parserXml();
}
/*生成XML文档*/
public static void createXml() {
//创建DOM树,Document 接口表示整个 HTML 或 XML 文档。从概念上讲,它是文档树的根,并提供对文档数据的基本访问
Document document;
try {
document = DocumentBuilderFactory.newInstance().newDocumentBuilder().newDocument();
//依次创建并添加节点元素
//根节点
Element root = document.createElement("employees");
document.appendChild(root);
//节点
Element employee = document.createElement("employee");
//姓名
Element name = document.createElement("name");
name.appendChild(document.createTextNode("丁洪亮"));
//年龄
Element age = document.createElement("age");
age.appendChild(document.createTextNode("20"));
//员工添加属性
employee.appendChild(name);
employee.appendChild(age);
//添加员工
root.appendChild(employee);
//创建DOM到文件转换器
Transformer tf = TransformerFactory.newInstance().newTransformer();
//转换源
DOMSource source = new DOMSource(document);
//设定转换编码
tf.setOutputProperty(OutputKeys.ENCODING, "gb2312");
//添加换行空白(没有这句的话XML文件无换行)(添加这句话之后就相当于每次多插入了n + 1个空白节点),解析的时候可以看出来
//tf.setOutputProperty(OutputKeys.INDENT, "yes");
//设定输出流
PrintWriter pw = new PrintWriter(new FileOutputStream("E:\\1.xml"));
//设定转换目标
StreamResult result = new StreamResult(pw);
//转换
tf.transform(source, result);
} catch (ParserConfigurationException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
} catch (TransformerConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (TransformerFactoryConfigurationError e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (TransformerException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
} //生成XML文件
/*解析XML文档*/
public static void parserXml() {
//DOM树,从某个XML文件获取
Document document;
try {
document = DocumentBuilderFactory.newInstance().newDocumentBuilder().parse("E:\\1.xml");
//获取DOM树中的所有节点
NodeList root = document.getChildNodes();
//循环获得每个员工节点
for(int i = 0; i < root.getLength(); ++i)
{
Node employees = root.item(i);
NodeList employees1 = employees.getChildNodes();
for(int j = 0; j < employees1.getLength(); ++j)
{
Node employee = employees1.item(j);
NodeList properties = employee.getChildNodes();
for(int k = 0; k < properties.getLength(); ++k)
{
Node property = properties.item(k);
System.out.println("k=" + k + "---" + property.getNodeName() + ":" + property.getTextContent());
}
}
}
} catch (SAXException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
上述代码运行结果如下。
生成的XML文件结构

解析结果
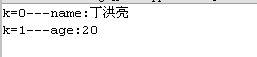
??????? 很容易发现,解析结果还可以令人满意,但是生成的XML文件没有换行,很难读。这是因为代码中的注释中说到的设置输出属性时,设置了不自动插入空白。




