英文原文:Non-blocking transactional atomicity
本文作者 Peter Bailis 是美国 Berkeley 的研究生,主要研究方向是分布式系统与数据库。作者目前主要的研究内容是分布式数据的一致性,尤其是如何调和 ACID 特性和分布式一致性模型,以及如何在理论和实际中更好的理解最终一致性。
作者将分布式系统中的事务定义为针对多个服务器的同时操作,本文主要讨论了分布式系统事务的原子性的一种实现算法。通常情况下原子性都是通过锁实现的,这个算法并没有使用锁,原理很简单,采用了简单的多版本控制和存储一些额外的元数据,虽然作者只是在实验环境中实现了这个算法,并没有投入到实际生产中,但是作者思考问题的方式值得参考。
分布式系统事务原子性
在现实的分布式系统中,多对象更新的操作很常见,但是实现起来却并不简单。同时更新两个或多个对象时,对于这些对象的其他读取者,原子性很重要:你的更新要么全部可见,要么全部不可见。
这里所说的原子性和线性一致并不是一个概念,数据一致性在 Gilbert 和 Lynch 证明 CAP 原理时被提到过,后来通常被称为原子一致性。而线性一致化关注实时的顺序操作,是一个单对象的问题。这里的“原子性”源于数据库环境(ACID 中的“A”),涉及对多个对象的执行和查询操作。为了避免混淆,我们称这个原子性为“事务原子性”。
许多场景中都会遇到这种问题,从社交网络图(例如 Facebook 的 TAO 系统,双向的朋友关系被保存在两个单向的指针中)到类似计数器(例如 Twitter 的 Rainbird 分层聚合器)和二级索引的分布式数据结构。本文中,我将假设我们的工作都是高可用的事务,原子性的多对象更新,或事务的原子性,是其首要特性。
现有的技术
多对象更新的事务操作通常采用以下三种策略之一:
锁
使用锁来同时更新多个项目。执行更新操作时加写锁,执行读操作时加读锁,就可以保证事务的原子性。但是在分布式环境中,局部故障和网络延迟都意味着锁操作可能会导致 Bad Time。
具体来讲,锁操作有可能会导致一些怪异的结果。如果客户端在持有锁时宕机,服务器本应该最终撤销这个锁。这需要某种形式的故障检测或超时(在异步网络中会导致一些尴尬的情况)以及在撤销锁前同时撤销以前的操作。但是在执行更新操作时阻塞读操作显然是不合理的,反之亦然。如果我们追求高可用性,锁不是一个值得考虑的方案。
实体组
将想要同时更新的对象放在一起。这种策略通常称为“实体组”,可以让事务性原子更简单:在一台机器上加锁很快,而且不会遇到分布式锁的局部故障和网络延迟的问题。不幸的是,这种解决方案会影响数据布局和分布,而且不适用于难于分割的数据。
Fuck-it模式
使用“fuck-it”模式,不进行任何并发控制的情况下更新所有的对象,并保持事务的原子性。这个策略是很常见的:扩展性良好,适用于任何系统,但是直到系统达到稳定状态后,才会提供原子性保证(例如聚合,或者说最终一致性)。
NBTA
在这篇文章中,作者会介绍一种简单的替代方案,作者称其为事务原子性的非阻塞实现,简称为 NBTA(Non-blocking transactional atomicity),使用多版本和一些额外的元数据在不使用锁的情况下,保证事务的原子性。具体来说,这种方案不会由于过程错误而阻塞读取和写入操作。关键的想法是避免执行局部更新,并且利用额外的元数据代替副本间的同步。
NBTA示例
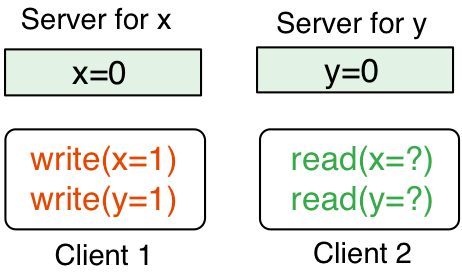
可以用这个简单的场景来说明 NBTA:有两个服务器,server for x上存储x,server for y 上存储y,初值都是0。假设有两个客户端,Client1 要执行写入操作,使x=1,y=1,Client2 要同时读取x和y,关于副本的问题稍后会讨论。作者将 Client1 要执行的写入操作称为一个事务,而这个事务的操作对象 server for x和 server for y 被称为事务兄弟。
good 和 pending
将每台服务器的存储分为两中状态:good 和 pending。要保证同属于一个事务的写入操作,如果其中一个操作被存储为 good 状态,这个事务的其它写入操作要么被存储为 good,要么被存储为 pending。比如在上面所说的场景中,如果x=1 在 server for x上被存储为 good,那么必须保证y=1 在 server for y 被存储为 good 或 pending。
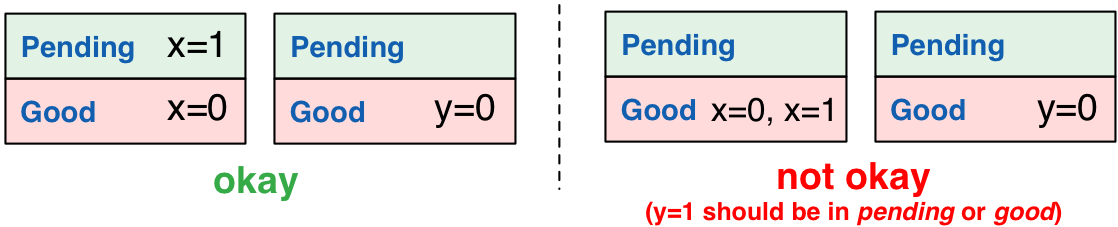
首先,各服务器会收到到写操作请求保存为 pending 状态,然后一旦服务器知晓(可能是异步的)某个写入操作相关的事务兄弟都已经将操作请求保存为 pending 状态,这个服务器就会更新这个操作为 good 状态。客户端进行两轮通信,就可以使服务器得到写操作已经稳定的信息:第一轮通信中,server for x 和 server for y 会将从 Client1 收到请求保存为 pending 状态,并将确认回复给 Client1,Client1 收到确认后会进行第二轮通信,通知 server for x 和 server for y 写操作已达到稳定状态。

竞争危害和指针
理想的状态是,只读取 good 状态的数据,就可以保证事务的原子性。但是存在一种竞争条件的情况:比如 server for x 已经更新x=1,并保存为 good 状态,但在其事务兄弟 server for y 中相关操作y=1 依旧是 pending 状态,Client2 如果只读取 good 状态的数据,得到的结果将是x=1,y=0,破坏了事务的原子性。我们希望这种情况下,第二个服务器能够自动调用 pending 状态的数据以供读取。

为了解决这个问题,可以在每个写入操作中加入一些额外的信息:事务兄弟的列表以及一个时间戳。这个时间戳是客户端进行多值更新前,为每个写操作唯一生成的,比如,可以是客户端 ID+ 本地时间或一个随机数。这样的话,当一个客户端读取 good 状态的数据时,还会读到时间戳和具有相同时间戳的事务兄弟的列表。客户端也会在发送读取请求附带一个时间戳,服务器会根据时间戳从 pending 或 good 中取出数据交付给客户端。如果客户端的请求中没有附带时间戳,服务器会将 good 中时间戳最高的值交付给客户端。
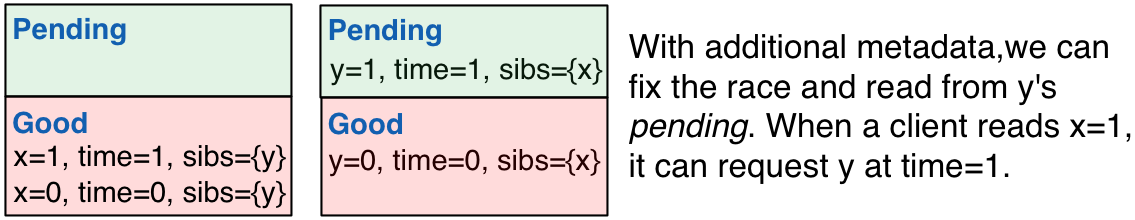
优化
以下是 NBTA 算法的一些优化:
pending 和 good 的规模
如果用在 good 中只保存最近的写入操作,那么一个写入操作的兄弟事务可能会被覆盖,为了避免这种情况的发生,服务器会在 good 中将历史数据保留一定的时间。
更快的写操作
有一种方案可以替代客户端的第二轮通信操作。服务器一旦将写操作存入 pending 中,就直接互相通信,可使用类似于 PAXOS 的算法实现。此外,客户端也可以异步发起第二轮通信。然而,为了确保客户端在这些情况下读取写操作,它们要保留元数据直到每个写操作都被存为 good 状态。
副本
目前为止的讨论都基于每个数据项只存储在一个服务器上。算法实现的前提条件是每个服务器的强一致性。服务器间的副本有两种情况:如果所有的客户端都只能访问一部分服务器,那么客户端只需要对这些对应的服务器集合进行更新,这组服务器都存有数据的副本。如果客户端可以访问任何服务器,那么需要花费较长的时间去同步数据。
读/写事务
以上讨论的算法同样适用于读/写操作。对于 ANSI 标准的可重复读模型,主要的问题是保证从一个事务的原子组中读取。可以在事务执行前,事先声明所有的读取操作或者通过类似向量时间的元数据实现。
元数据的规模
最谨慎的做法是将元数据一直保存,但是也可以在写操作在所有服务器中都达到 good 状态时,将元数据删除。
算法的实现
作者采用 LevelDB 数据库实现了 NBTA 算法及其改进。在 Yahoo!的云平台上,8 个操作的 NBTA 事务可以达到最终一致性的 33%(所有都是写操作)至 95.2%(所有都是读操作)峰值吞吐量。并且这种实现是线性扩展的,运行 50 个 EC2 实例,对于长度为 8 的事务(50% 的读操作,50% 的写操作),可以达到每秒执行 250000 次操作。
实验结果表明 NBTA 的性能大大优于基于锁的操作,因为不会发生阻塞。主要的花销来自于元数据以及将写入操作从 pending 更新为 good。基于这些结果,作者已经开始将 NBTA 应用于其它数据存储和二级索引上。
结论
这篇文章展现了如何在不使用锁的情况下,实现在任意数据分片的原子性多对象更新。数据库中有很多类似于 NBTA 的算法。例如客户端第二轮通信的优化是通过 PAXOS 的算法实现的,使用额外的元数据保持并发更新类似于B树或其它非锁的数据结构。当然,多版本并发控制和基于时间戳的并发控制在数据库系统中也都有悠久的历史。但是 NBTA 的关键是实现事务的原子性,同时避免中央集权的时间戳或并发控制机制。具体来说要在数据读取操作前达到一个稳定状态,主要的挑战是解决竞争条件。在实际中,相比其它基于锁的技术,这个算法表现得很好。