======张峻崇 原创。转载请注明出处。======
又是快一年没写博客了,2013年也只剩尾巴,也不知道今年都忙了些什么。写这篇文章的目的,主要是把今年以来学习的一些东西积淀下来,同时作为之前文章《高性能分布式计算与存储系统设计概要》的补充与提升,然而本人水平非常有限,回头看之前写的文章也有许多不足,甚至是错误,希望同学们看到了错误多多见谅,更欢迎与我讨论并指正。
我大概是从2010年底起开始进入高并发、高性能服务器和分布式这一块领域的研究,到现在也差不多有三年,但其实很多东西仍然是一知半解,我所提到的许许多多概念,也许任何一个我都不能讲的很清楚,还需要继续钻研。但我们平时在工作和学习中,多半也只能从这种一知半解开始,慢慢琢磨,不断改进。
好了,下面开始说我们今天要设计的系统。
这个系统的目标很明确,针对千万级以上PV的网站,设计一套用于后台的高并发的分布式处理系统。这套系统包含业务逻辑的处理、各种计算、存储、日志、备份等方面内容,可用于类微博,SNS,广告推送,邮件等有大量线上并发请求的场景。
如何抗大流量高并发?(不要告诉我把服务器买的再好一点)说起来很简单,就是“分”,如何“分”,简单的说就是把不同的业务分拆到不同的服务器上去跑(垂直拆分),相同的业务压力分拆到不同的服务器去跑(水平拆分),并时刻不要忘记备份、扩展、意外处理等讨厌的问题。说起来都比较简单,但设计和实现起来,就会比较困难。以前我的文章,都是“从整到零”的方式来设计一个系统,这次咱们就反着顺序来。
那我们首先来看,我们的数据应该如何存储和取用。根据我们之前确定的“分”的方法,先确定以下2点:
(1)我们的分布式系统,按不同的业务,存储不同的数据;(2)同样的业务,同一个数据应存储多份,其中有的存储提供读写,而有的存储只提供读。
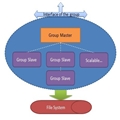
好,先解释下这2点。对于(1)应该容易理解,比如说,我这套系统用于微博(就假想我们做一个山寨的推特吧,给他个命名就叫“山推” 好了,以下都叫山推,Stwi),那么,“我关注的人”这一个业务的数据,肯定和“我发了的推文”这个业务的数据是分开存储的,那么我们现在把,每一个业务所负责的数据的存储,称为一个group。即以group的方式,来负责各个业务的数据的存储。接下来说(2),现在我们已经知道,数据按业务拆到group里面去存取,那么一个group里面又应该有哪些角色呢?自然的,应该有一台主要的机器,作为group的核心,我们称它为Group Master,是的,它就是这个group的主要代表。这个group的数据,在Group Master上应该都能找到,进行读写。另外,我们还需要一些辅助角色,我们称它们为Group Slaves,这些slave机器做啥工作呢?它们负责去Group Master处拿数据,并尽量保持和它同步,并提供读服务。请注意我的用词,“尽量”,稍后将会解释。现在我们已经有了一个group的基本轮廓:
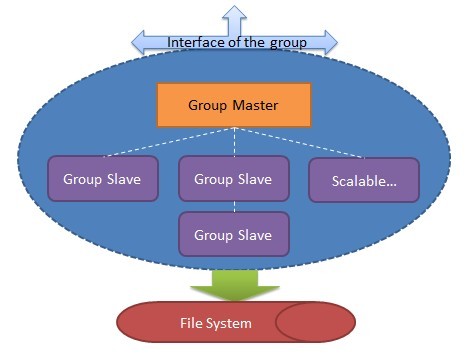
一个group提供对外的接口(废话否则怎么存取数据),group的底层可以是实际的File System,甚至是HDFS。Group Master和Group Slave可以共享同一个File System(用于不能丢数据的强一致性系统),也可以分别指向不同的File System(用于弱一致性,允许停写服务和系统宕机时丢数据的系统),但总之应认为这个"File System"是无状态,有状态的是Group Master和各个Group Slave。
下面来说一个group如何工作,同步等核心问题。首先,一个group的Group Master和Group Slave
间应保持强一致性还是弱一致性(最终一致性)应取决于具体的业务需求,以我们的“山推”来说,Group Master和Group Slave并不要求保持强一致性,而弱一致性(最终一致性)即能满足要求,为什么?因为对于“山推”来讲,一个Group Master写了一个数据,而另一个Group Slave被读到一个“过期”(因为Group Master已经写,但此Group Slave还未更新此数据)的数据通常并不会带来大问题,比如,我在“山推”上发了一个推文,“关注我的人”并没有即时同步地看到我的最新推文,并没有太大影响,只要“稍后”它们能看到最新的数据即可,这就是所谓的最终一致性。但当Group Master挂掉时,写服务将中断一小段时间由其它Group Slave来顶替,稍后还要再讲这个问题。假如我们要做的系统不是山推,而是淘宝购物车,支付宝一类的,那么弱一致性(最终一致性)则很难满足要求,同时写服务挂掉也是不能忍受的,对于这样的系统,应保证“强一致性”,保证不能丢失任何数据。
接下来还是以我们的“山推“为例,看看一个group如何完成数据同步。假设,现在我有一个请求要写一个数据,由于只有Group Master能写,那么Group Master将接受这个写请求,并加入写的队列,然后Group Master将通知所有Group Slave来更新这个数据,之后这个数据才真正被写入File System。那么现在就有一个问题,是否应等所有Group Slave都更新了这个数据,才算写成功了呢?这里涉及一些NWR的概念,我们作一个取舍,即至少有一个Group Slave同步成功,才能返回写请求的成功。这是为什么呢?因为假如这时候Group Master突然挂掉了,那么我们至少可以找到一台Group Slave保持和Group Master完全同步的数据并顶替它继续工作,剩下的、其它的Group Slave将“异步”地更新这个新数据,很显然,假如现在有多个读请求过来并到达不同的Group Slave节点,它们很可能读到不一样的数据,但最终这些数据会一致,如前所述。我们做的这种取舍,叫“半同步”模式。那之前所说的强一致性系统应如何工作呢?很显然,必须得等所有Group Slave都同步完成才能返回写成功,这样Group Master挂了,没事,其它Group Slave顶上就行,不会丢失数据,但是付出的代价就是,等待同步的时间。假如我们的group是跨机房、跨地区分布的,那么等待所有Group Slave同步完成将是很大的性能挑战。所以综合考虑,除了对某些特别的系统,采用“最终一致性”和“半同步”工作的系统,是符合高并发线上应用需求的。而且,还有一个非常重要的原因,就是通常线上的请求都是读>>写,这也正是“最终一致性”符合的应用场景。
好,继续。刚才我们曾提到,如果Group Master宕机挂掉,至少可以找到一个和它保持同不的Group Slave来顶替它继续工作,其它的Group Slave则“尽量”保持和Group Master同步,如前文所述。那么这是如何做到的呢?这里涉及到“分布式选举”的概念,如Paxos协议,通过分布式选举,总能找到一个最接近Group Master的Group Slave,来顶替它,从而保证系统的可持续工作。当然,在此过程中,对于最终一致性系统,仍然会有一小段时间的写服务中断。现在继续假设,我们的“山推”已经有了一些规模,而负责“山推”推文的这个group也有了五台机器,并跨机房,跨地区分布,按照上述设计,无论哪个机房断电或机器故障,都不会影响这个group的正常工作,只是会有一些小的影响而已。
那么对于这个group,还剩2个问题,一是如何知道Group Master挂掉了呢?二是在图中我们已经看到Group Slave是可扩展的,那么新加入的Group Slave应如何去“偷”数据从而逐渐和其它节点同步呢?对于问题一,我们的方案是这样的,另外提供一个类似“心跳”的服务(由谁提供呢,后面我们将讲到的Global Master将派上用场),group内所有节点无论是Group Master还是Group Slave都不停地向这个“心跳”服务去申请一个证书,或认为是一把锁,并且这个锁是有时间的,会过期。“心跳”服务定期检查Group Master的锁和其有效性,一旦过期,如果Group Master工作正常,它将锁延期并继续工作,否则说明Group Master挂掉,由其它Group Slave竞争得到此锁(分布式选举),从而变成新的Group Master。对于问题二,则很简单,新加入的Group Slave不断地“偷”老数据,而新数据总由于Group Master通知其更新,最终与其它所有结点同步。(当然,“偷”数据所用的时间并不乐观,通常在小时级别)
中篇链接:http://www.cnblogs.com/ccdev/p/3340484.html