class="topic_img" alt=""/>
class="topic_img" alt=""/>
英文原文:Reddit’s empire is founded on a flawed algorithm
Reddit 的源码中存在一个 bug。这个 bug 目前还存在他们的平台产品之中,并且已经存在了多年。这个 bug 与应用于整个站点最重要的算法之一有关——针对“热点”链接受欢迎度的排序算法。这个 bug 也导致了真实显见的负面影响,并且这个问题多次报告给 Reddit 的技术组,但是一直没有被修复。
缺陷
Reddit 需要判断当前哪篇文章比较热门。新文章比旧文章更热门一些,拥有更多正面投票的文章比有很少投票的文章更好,而大部分投负面票的文章则垫底。这些规则比较容易计算。针对发布时间和投票可以确定一个确切的数值,然后与一个常量系数,就能计算出每篇文章的的受欢迎程度1。
魔鬼在于细节,根据 GitHub 中的源码,目前的实现是这样的。
seconds = date - 1134028003
seconds 是根据时间变化的变量,基于 Unix 时间戳。这样做合情理,时间总是累加的,所以每一个新文章发布都较之前发布的文章在时间上拥有更高的分数值。
s = score (ups, downs) order = log10(max (abs (s), 1)) if s > 0: sign = 1 elif s < 0: sign = -1 else: sign = 0
投票部分计算根据公式有两个部分,sign 变量简单地记录总投票数是正面还是反面的。如果文章收到的正面评分比负面评分更多,sign 就是1;如果负面评分更多,sign 的值就是-1.其他变量,order 是投票分数绝对值的取 log102对数。
真正的问题是,和许多问题一样,从两个角色的交换。
return round (order + sign * seconds / 45000, 7)
这里我们计算得到了最终的分数。Seconds 是一个很大的正值,而 order 总是返回为正——由于这里使用了的绝对值,所以,尽管如一个负数-389 也会得到和 order 值为 389 一样的结果,我们需要通过 sign 来调整我们的结果,这样,负面意见的文章会被排在后面。但是这里的代码使用了 sign 乘于时间 seconds,而不是 sign 乘于 order。
而对于正面评价的文章,则没有影响,由于符号位为1,所以 order 和 seconds 相加,计算没有问题。
对于负面评价文章又发生了什么呢?sign 值为-1,所以值比较大的 seconds 变量会变为负值,而使用一个正面评价的 order 值与之相加,因此会导致几个问题。
假设两篇文章,相距 5 秒发布。每一个都收到两个父母评价,seconds 对于新文章值更大一些,但是因为 sign 为负值,新的文章评分反而比旧的文章低。
假定还有两篇文章同时发布,一篇文章收到了 10 个差评,另外一篇文章收到五个差评。由于 seconds 一样,符号值 sign 都是-1,但是得到-10 评价的文章 order 值更高。所以,-10 评分的文章反而排序在得到-5 评分的文章前面,尽管人们讨厌它两倍。
现在假定一篇文章在一年前发布,另外一篇文章刚刚才发布。去年发布的文章有两个正面评分,今天刚发布的文章有两个差评。这里有点不同——今天发布的文章可能得到了差评开始,不过也可能接下来收到好评。不过,在当前的实现3中,由于今天文章有两个差评,从而导致其热度评分反而比去年的文章更低。
后续
这并不是一个假设的漏洞,我好奇地去看了一些 Reddit 的公共库的代码是否也应用在他们当前的产品中,我找到近期发布的一些不太活跃的文章,给它差评使得它的总分是负分。就是这样的文章,不但跌出了第一页(这一页当中还有几个月前的文章),这个是热度排序算法的结果。我觉得这个结果比较糟糕,又移除了我的差评,但是这个文章并没有恢复到排名之中4。
事实上,通过操作查询字符串,你可以发现一个奇怪的陷阱,糟糕的文章在莫名的角落缓慢地腐化5(译者:我猜作者的意思应该是让人讨厌的文章总数显示在显眼的地方)。下面的截图来自 iphone 版的 subReddit 这些不幸的文章。
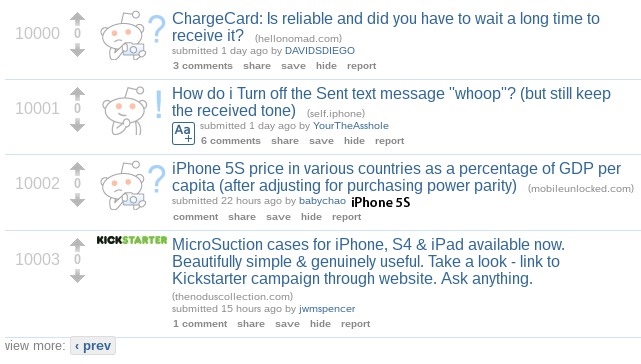
这些文章是一些伤心的、害怕、孤独的文章。但是在显著位置,并且按时间顺序排列,就如预料的一样。
这个缺陷为一些故意破坏这个系统的人提供了一扇门。假设有一个 subReddit,/r/BirdPics,投票给一些鸟类图片6。攻击者不喜欢海雀,并且希望把所有的海雀图片都驱逐出首页,这个攻击者可以对每一张海雀图片都给差评,不过这也可能被那些喜欢海雀的人给好评而消弱。平均来说,任何时刻查看首页的人的大概是 350 人,为了阻止这种恶意差评需要许多的评价较量。
不过,攻击者可以小心留意那些最近发布的图片,这个时候一旦有海雀图片被发布,攻击者立即给他一个差评。如果攻击者先投票,那么这篇文章总分就是一个差评并且会被逐出首页,在首页上再也看不到这篇文章。攻击者唯一需要担心的是有人会去查看最新排序文章列表,这里投票并不影响排序。我们假定 350 人中只有 10 人会去查看最新文章列表,因此攻击者只需用使用 10 个虚假账号来应对这些人,而不是需要近 300 个账号来对付首页上的所有人。就这样,攻击者可以清除 subreddit 上的所有海雀图片,这些海雀就再也没人注意。
补救措施
我不是第一个发现这个问题的人,Jonathan Rochkind 在他的发表的一篇言辞详尽的话题中谈及了该问题。不过一位 Reddit 的开发者告诉他,他弄错了,当前的算法没有问题。
我在开发者社区发布了一篇请求修复该 bug 的文章,也被一个开发者告知,就是这样设计的。我不懂,也没有得到一个令人满意的解释,在何种意义上这种荒谬的行为将是“就是这样设计”的。但很明显,Reddit 对解决这个问题不感兴趣,这一行为可能会持续许多年。
结局
程序员往往围绕着规则的一致性寻找公平正义。这也是为什么我们中的许多人发现世俗领域关系或政治如此棘手的,以及为什么我们中的许多人第一时间被计算机科学吸引。在计算机世界,一切都是严格确定的。如果发生了一些未定义的事情,那也只是因为我们对系统的理解不完整7。对于正确性,capital-R 就是一个可理解的系统并且精确执行。
我们拥有这样的世界观,而一个明显的 bug 被散播看起来是不公正的。我和其他发现这个问题的开发者看起来对这个算法的理解比那些 Reddit 回应我们的员工更深入一些。对于这个没有被修补令人惊讶且违反直觉的行为,我们肯定是对的。我们是对的,而 Reddit 搞错了。因为 Reddit 是一个流行站点,并且拥有大量的用户,以及大量的现金。这些都建立在一个明显错误的组件之上。
这里的道德是什么?也许就是一个没有有效测试使得这个系统不能被理解,或者最终变为一个“可以工作,但是停止问问题”的系统。也许追求完美是好的一面的敌人,更糟反而更好8,这样的分歧使我远离喋喋不休的争吵9。也许好产品和好的技术实现存在一定的距离,而硬性的数据总是能保证正面的体验。
也许这没有道德,是 Reddit 搞砸了。这原本会伤及它自身,但是没有,也可能不会。他们错了,但是没有导致实际的错误,因为没有一个大写 W Wrong。我们都应当编写有责任的代码,这里没有一个数学上帝可以有一天评判 Reddit 在做算法时的罪行。世界就是一个有缺陷的世界,曾经是,也一直都会如此。
脚注:
,我们可以得到 ID 值 1s33tt。然后,插入下面的链接,取代必要的部分:http://www.reddit.com/r/SUBREDDIT/?count=9999&after=t3_ID,。我们的 URL 会变成http://www.reddit.com/r/birdpics/?count=9999&after=t3_1s33tt。这里 ID 值被 t3_前缀展开,然后你可以随意改变 count 值,这个值可以手动调节。翻译: 伯乐在线 - zzzworm
译文链接: http://blog.jobbole.com/53406/