1.Collection List Set Map �������
��Щ��������class="hilite1">Java�еļ��ϣ�������Ҫ����Ԫ���Ƿ������Ƿ���ظ�������������䣬�Ա�ǡ����ʹ�ã���Ȼ������ͬ������IJ��죬����һƪ������¡�
?
?
�����
����Ԫ���ظ���
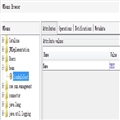
Collection
��
��
List
��
��
Set
AbstractSet
��
��
HashSet
TreeSet
�ǣ���hashu.html" target="_blank">����������
Map
AbstractMap
��
ʹ��key-value��ӳ��ʹ洢���ݣ�Key����Ωһ��value�����ظ�
HashMap
TreeMap
�ǣ��ö���������
?
List�ӿ���Collection�����˼����䣬���ľ���ʵ���ೣ�õ���ArrayList��LinkedList������Խ��κζ����ŵ�һ��List�����У�������Ҫʱ����ȡ����ArrayList���������п��Կ�������һ�������������ʽ���д洢�����������������ٶȼ��죬��LinkedList���ڲ�ʵ�������������ʺ����������м���ҪƵ�����в����caozuo.html" target="_blank">ɾ���������ھ���Ӧ��ʱ���Ը�����Ҫ����ѡ��ǰ��˵��Iteratorֻ�ܶ�����������ǰ��������ListIterator��̳���Iterator��˼�룬���ṩ�˶�List����˫������ķ�����?
Set�ӿ�Ҳ��Collection��һ����չ������List��ͬ��ʱ����Set�еĶ���Ԫ�ز����ظ���Ҳ����˵�㲻�ܰ�ͬ���Ķ������η���ͬһ��Set�����С����ij��þ���ʵ����HashSet��TreeSet�ࡣHashSet�ܿ��ٶ�λһ��Ԫ�أ�������ŵ�HashSet�еĶ�����Ҫʵ��hashCode()��������ʹ����ǰ��˵���Ĺ�ϣ����㷨����TreeSet�������е�Ԫ�ذ����ţ����Ҫ����������еĶ����ǿ�����ģ�����õ��˼��Ͽ���ṩ����������ʵ����Comparable��Comparator��һ�����ǿ�����ģ�����Ӧ��ʵ��Comparable�ӿڡ���ʱ����������ͬ�������㷨���ǾͲ���Ҫ��ÿ�ֱ��ظ�������ͬ�������㷨��ֻҪʵ��Comparator�ӿڼ��ɡ����Ͽ���л���������ʵ�õĹ����ࣺCollections��Arrays��Collections�ṩ�˶�һ��Collection�����������������ơ����Һ�����һЩ�dz����õķ�����Arrays���Ƕ�һ������������ƵIJ�����?
Map��һ�ְѼ������ֵ������й�������������һ��ֵ�����ֿ�����һ��Map���������ƣ������Ϳ��γ�һ���༶ӳ�䡣���ڼ�������˵����Setһ����һ��Map�����еļ����������ظ�������Ϊ�˱��ֲ��ҽ����һ����;���������������һ����������õ��Ǹ�����������Ӧ��ֵ����ʱ���������ˣ�������õ��IJ�����������Ǹ�ֵ���������ɻ��ң����Լ���Ψһ�Ժ���Ҫ��Ҳ�Ƿ��ϼ��ϵ����ʵġ���Ȼ��ʹ�ù����У�ij��������Ӧ��ֵ������ܻᷢ���仯����ʱ�ᰴ�����һ���ĵ�ֵ���������Ӧ������ֵ������û��Ψһ�Ե�Ҫ������Խ�����������ӳ�䵽һ��ֵ�����ϣ��ⲻ�ᷢ���κ����⣨���������ʹ��ȴ���ܻ���ɲ��㣬�㲻֪����õ��ĵ�������һ��������Ӧ��ֵ����Map�����ֱȽϳ��õ�ʵ�֣�HashMap��TreeMap��HashMapҲ�õ��˹�ϣ����㷨���Ա���ٲ���һ������TreeMap���ǶԼ������ţ����������һЩ��չ�ķ���������firstKey(),lastKey()�ȣ��㻹���Դ�TreeMap��ָ��һ����Χ��ȡ������Map������ֵ�Ĺ����ܼ���pub(Object key,Object value)�������ɽ�һ������һ��ֵ�������������get(Object key)�ɵõ����key��������Ӧ��ֵ����
2.List��vector��set��map����������ϵ
��ʹ��Java��ʱ�����Ƕ�������ʹ�ü��ϣ�Collection����ʱ����Java?API�ṩ�˶��ּ��ϵ�ʵ�֣�����ʹ�ú����Ե�ʱ��ƵƵ���������ġ�����?��?:������Ҫ�������Ե�ʱ��Collection��List��Set
Map��HashMap��HashTable
���������֮��ѡ��
һ��Array �� Arrays
Java���С��洢���������һ��������������array������Ч�ʵ�һ�֡�
1��
Ч�ʸߣ��������̶�������̬�ı䡣
array����һ��ȱ���ǣ����ж�����ʵ�ʴ��ж���Ԫ�أ�lengthֻ�Ǹ�������array��������
2��Java����һ��Arrays�࣬ר����������array��
arrays��ӵ��һ��static������
equals()���Ƚ�����array�Ƿ���ȡ�arrayӵ����ͬԪ�ظ����������ж�ӦԪ��������ȡ�
fill()����ֵ����array�С�
sort()��������array��������
binarySearch()�����ź����array��Ѱ��Ԫ�ء�
System.arraycopy()��array�ĸ��ơ�
����Collection �� Map
��д����ʱ��֪��������Ҫ���ٶ�����Ҫ�ڿռ䲻��ʱ�Զ���������������Ҫʹ��������⣬array�����á�
1��Collection �� Map ������
������ÿ��Ϊ֮���洢��Ԫ�ظ�����ͬ��
Collection�����ߣ�ÿ��λ��ֻ��һ��Ԫ�ء�
Map�����ߣ����� key-value pair�����С�����ݿ⡣
2���������µ������ϵ
Collection --List�� �����ض�����洢Ԫ�ء�����ȡ������˳����ܺͷ���˳��ͬ��
--ArrayList / LinkedList / Vector --Set �� ���ܺ����ظ���Ԫ��
--HashSet / TreeSet
Map
--HashMap
--HashTable
--TreeMap
3����������
* List��Set��Map�����ж���һ����ΪObject�ͱ�
* Collection��List��Set��Map���ǽӿڣ�����ʵ������
�̳������ǵ� ArrayList, Vector, HashTable, HashMap�Ǿ���class����Щ�ſɱ�ʵ������
* vector����ȷ��֪���������еĶ�������ʲô�ͱ�vector�����б߽��顣
����Collections
Collections����Լ������һ�������ࡣ�ṩ��һϵ����̬����ʵ�ֶԸ��ּ��ϵ������������߳���ȫ���Ȳ�����
�൱�ڶ�Array�������Ʋ������ࡪ��Arrays��
�磬Collections.max(Collection coll); ȡcoll������Ԫ�ء�
Collections.sort(List list); ��list��Ԫ������
�ġ����ѡ��
1���������Array��������ȡ
* ��������ܳ��ж������ã�ָ������ָ�룩�������ǽ�������Ϣcopyһ��������ijλ�á�
* һ�����������������ڣ�����ʧ�˸ö�����ͱ���Ϣ��
2��
* �ڸ���Lists�У���õ���������ArrayList��Ϊȱʡѡ�����롢ɾ��Ƶ��ʱ��ʹ��LinkedList()��
Vector���DZ�ArrayList��������Ҫ��������ʹ�á�
* �ڸ���Sets�У�HashSetͨ������HashTree�����롢���ң���ֻ�е���Ҫ����һ��������������У�����TreeSet��
HashTree���ڵ�Ψһ���ɣ��ܹ�ά������Ԫ�ص�����״̬��?
* �ڸ���Maps��
HashMap���ڿ��ٲ��ҡ�
* ��Ԫ�ظ����̶�����Array����ΪArrayЧ������ߵġ�
���ۣ���õ���ArrayList��HashSet��HashMap��Array��
ע�⣺
1��Collectionû��get()������ȡ��ij��Ԫ�ء�ֻ��ͨ��iterator()����Ԫ�ء�
2��Set��Collectionӵ��һģһ���Ľӿڡ�
3��List������ͨ��get()������һ��ȡ��һ��Ԫ�ء�ʹ��������ѡ��һ�Ѷ����е�һ����get(0)...��(add/get)
4��һ��ʹ��ArrayList����LinkedList������ջstack������queue��
5��Map�� put(k,v) / get(k)��������ʹ��containsKey()/containsValue()����������Ƿ���ij��key/value��
HashMap�����ö����hashCode�������ҵ�key��
* hashing ��ϣ����ǽ��������Ϣ����һЩת���γ�һ����һ����intֵ�����ֵ�洢��һ��array�С�
���Ƕ�֪�����д洢�ṹ�У�array�����ٶ������ġ����ԣ����Լ��ٲ��ҡ�
������ײʱ����arrayָ����values����������ÿ��λ����������һ��������
6��Map��Ԫ�أ����Խ�key���С�value���е�����ȡ������ʹ��keySet()��ȡkey���У���map�е�����keys����һ��Set��
ʹ��values()��ȡvalue���У���map�е�����values����һ��Collection��
Ϊʲôһ������Set��һ������Collection��������Ϊ��key���Ƕ�һ���ģ�value�����ظ���
?
from��http://blog.csdn.net/zhengqiqiqinqin/article/details/8434132