在前面的几篇文章中,我们介绍了EasyPR中车牌定位模块的相关内容。本文开始分析车牌定位模块后续步骤的车牌判断模块。车牌判断模块是EasyPR中的基于机器学习模型的一个模块,这个模型就是作者前文中从机器学习谈起中提到的SVM(支持向量机)。
我们已经知道,车牌定位模块的输出是一些候选车牌的图片。但如何从这些候选车牌图片中甄选出真正的车牌,就是通过SVM模型判断/预测得到的。




![]()

图1 从候选车牌中选出真正的车牌
简单来说,EasyPR的车牌判断模块就是将候选车牌的图片一张张地输入到SVM模型中,然后问它,这是车牌么?如果SVM模型回答不是,那么就继续下一张,如果是,则把图片放到一个输出列表里。最后把列表输入到下一步处理。由于EasyPR使用的是列表作为输出,因此它可以输出一副图片中所有的车牌,不像一些车牌识别程序,只能输出一个车牌结果。

![]()
图2 EasyPR输出多个车牌
现在,让我们一步步地,进入这个SVM模型的核心看看,它是如何做到判断一副图片是车牌还是不是车牌的?本文主要分为三个大的部分:
一.SVM应用
人类是如何判断一个张图片所表达的信息呢?简单来说,人类在成长过程中,大脑记忆了无数的图像,并且依次给这些图像打上了标签,例如太阳,天空,房子,车子等等。你们还记得当年上幼儿园时的那些教科书么,上面一个太阳,下面是文字。图像的组成事实上就是许多个像素,由像素组成的这些信息被输入大脑中,然后得出这个是什么东西的回答。我们在SVM模型中一开始输入的原始信息也是图像的所有像素,然后SVM模型通过对这些像素进行分析,输出这个图片是否是车牌的结论。
图3 通过图像来学习
SVM模型处理的是最简单的情况,它只要回答是或者不是这个“二值”问题,比从许多类中检索要简单很多。
我们可以看一下SVM进行判断的代码:
int CPlateJudge::plateJudge(const vector<Mat>& inVec, vector<Mat>& resultVec) { int num = inVec.size(); for (int j = 0; j < num; j++) { Mat inMat = inVec[j]; Mat p = histeq(inMat).reshape(1, 1); p.convertTo(p, CV_32FC1); int response = (int)svm.predict(p); if (response == 1) { resultVec.push_back(inMat); } } return 0; }View Code
首先我们读取这幅图片,然后把这幅图片转为OPENCV需要的格式;
Mat p = histeq(inMat).reshape(1, 1); p.convertTo(p, CV_32FC1);
接着调用svm的方法predict;
int response = (int)svm.predict(p);
perdict方法返回的值是1的话,就代表是车牌,否则就不是;
if (response == 1) { resultVec.push_back(inMat); }
svm是类CvSVM的一个对象。这个类是opencv里内置的一个机器学习类。
CvSVM svm;
opencv的CvSVM的实现基于libsvm(具体信息可以看opencv的官方文档的介绍 )。
libsvm是台湾大学林智仁(Lin Chih-Jen)教授写的一个世界知名的svm库(可能算是目前业界使用率最高的一个库)。官方主页地址是这里。
libsvm的实现基于SVM这个算法,90年代初由Vapnik等人提出。国内几篇较好的解释svm原理的博文:cnblog的LeftNotEasy(解释的易懂),pluskid的博文(专业有配图)。
作为支持向量机的发明者,Vapnik是一位机器学习界极为重要的大牛。最近这位大牛也加入了Facebook。
 图4 SVM之父Vapnik
图4 SVM之父Vapnik
svm的perdict方法的输入是待预测数据的特征,也称之为features。在这里,我们输入的特征是图像全部的像素。由于svm要求输入的特征应该是一个向量,而Mat是与图像宽高对应的矩阵,因此在输入前我们需要使用reshape(1,1)方法把矩阵拉伸成向量。除了全部像素以外,也可以有其他的特征,具体看第三部分“SVM调优”。
predict方法的输出是float型的值,我们需要把它转变为int型后再进行判断。如果是1代表就是车牌,否则不是。这个"1"的取值是由你在训练时输入的标签决定的。标签,又称之为label,代表某个数据的分类。如果你给SVM模型输入一个车牌,并告诉它,这个图片的标签是5。那么你这边判断时所用的值就应该是5。
以上就是svm模型判断的全过程。事实上,在你使用EasyPR的过程中,这些全部都是透明的。你不需要转变图片格式,也不需要调用svm模型preditct方法,这些全部由EasyPR在内部调用。
那么,我们应该做什么?这里的关键在于CvSVM这个类。我在前面的机器学习论文中介绍过,机器学习过程的步骤就是首先你搜集大量的数据,然后把这些数据输入模型中训练,最后再把生成的模型拿出来使用。
训练和预测两个过程是分开的。也就是说你们在使用EasyPR时用到的CvSVM类是我在先前就训练好的。我是如何把我训练好的模型交给各位使用的呢?CvSVM类有个方法,把训练好的结果以xml文件的形式存储,我就是把这个xml文件随EasyPR发布,并让程序在执行前先加载好这个xml。这个xml的位置就是在文件夹Model下面--svm.xml文件。
 图5 model文件夹下的svm.xml
图5 model文件夹下的svm.xml
如果看CPlateJudge的代码,在构造函数中调用了LoadModel()这个方法。
CPlateJudge::CPlateJudge() { //cout << "CPlateJudge" << endl; m_path = "model/svm.xml"; LoadModel(); }
LoadModel()方法的主要任务就是装载model文件夹下svm.xml这个模型。
void CPlateJudge::LoadModel() { svm.clear(); svm.load(m_path.c_str(), "svm"); }
如果你把这个xml文件换成其他的,那么你就可以改变EasyPR车牌判断的内核,从而实现你自己的车牌判断模块。
后面的部分全部是告诉你如何有效地实现一个自己的模型(也就是svm.xml文件)。如果你对EasyPR的需求仅仅在应用层面,那么到目前的了解就足够了。如果你希望能够改善EasyPR的效果,定制一个自己的车牌判断模块,那么请继续往下看。
二.SVM训练
恭喜你!从现在开始起,你将真正踏入机器学习这个神秘并且充满未知的领域。至今为止,机器学习很多方法的背后原理都非常复杂,但众多的实践都证明了其有效性。与许多其他学科不同,机器学习界更为关注的是最终方法的效果,也就是偏重以实践效果作为评判标准。因此非常适合从工程的角度入手,通过自己动手实践一个项目里来学习,然后再转入理论。这个过程已经被证明是有效的,本文的作者在开发EasyPR的时候,还没有任何机器学习的理论基础。后来的知识是将通过学习相关课程后获取的。
简而言之,SVM训练部分的目标就是通过一批数据,然后生成一个代表我们模型的xml文件。
EasyPR中所有关于训练的方法都可以在svm_train.cpp中找到(1.0版位于train/code文件夹下,1.1版位于src/train文件夹下)。
一个训练过程包含5个步骤,见下图: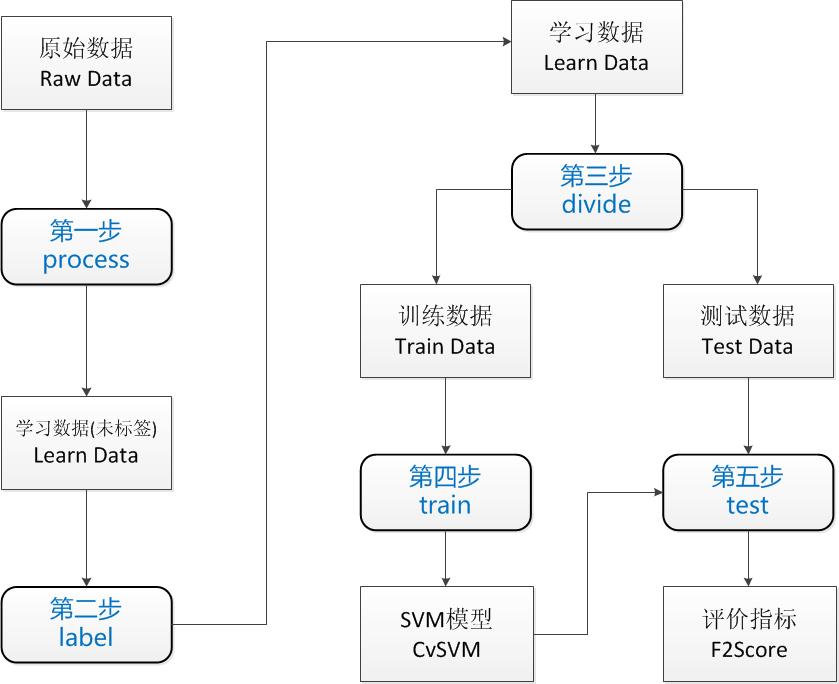
图6 一个完整的SVM训练流程
下面具体讲解一下这5个步骤,步骤后面的括号里代表的是这个步骤主要的输入与输出。
1. preprocss(原始数据->学习数据(未标签))
预处理步骤主要处理的是原始数据到学习数据的转换过程。原始数据(raw data),表示你一开始拿到的数据。这些数据的情况是取决你具体的环境的,可能有各种问题。学习数据(learn data),是可以被输入到模型的数据。
为了能够进入模型训练,必须将原始数据处理为学习数据,同时也可能进行了数据的筛选。比方说你有10000张原始图片,出于性能考虑,你只想用1000张图片训练,那么你的预处理过程就是将这10000张处理为符合训练要求的1000张。你生成的1000张图片中应该包含两类数据:真正的车牌图片和不是车牌的图片。如果你想让你的模型能够区分这两种类型。你就必须给它输入这两类的数据。
通过EasyPR的车牌定位模块PlateLocate可以生成大量的候选车牌图片,里面包括模型需要的车牌和非车牌图片。但这些候选车牌是没有经过分类的,也就是说没有标签。下步工作就是给这些数据贴上标签。
2. label (学习数据(未标签)->学习数据)
训练过程的第二步就是将未贴标签的数据转化为贴过标签的学习数据。我们所要做的工作只是将车牌图片放到一个文件夹里,非车牌图片放到另一个文件夹里。在EasyPR里,这两个文件夹分别叫做HasPlate和NoPlate。如果你打开train/data/plate_detect_svm后,你就会看到这两个压缩包,解压后就是打好标签的数据(1.1版本在同层learn data文件夹下面)。
如果有人问我开发一个机器学习系统最耗时的步骤是哪个,我会毫不犹豫的回答:“贴标签”。诚然,各位看到的压缩包里已经有打好标签的数据了。但各位可能不知道作者花在贴这些标签上的时间。粗略估计,整个EasyPR开发过程中有70%的时间都在贴标签。SVM模型还好,只有两个类,训练数据仅有1000张。到了ANN模型那里,字符的类数有40多个,而且训练数据有4000张左右。那时候的贴标签过程,真是不堪回首的回忆,来回移动文件导致作者手经常性的非常酸。后来我一度想找个实习生帮我做这些工作。但转念一想,这些苦我都不愿承担,何苦还要那些小伙子承担呢。“己所不欲,勿施于人”。算了,既然这是机器学习者的命,那就欣然接受吧。幸好在这段磨砺的时光,我逐渐掌握了一个方法,大幅度减少了我贴标签的时间与精力。不然,我可能还未开始写这个系列的教程,就已经累吐血了。开发EasyPR1.1版本时,新增了一大批数据,因此又有了贴标签的过程。幸好使用这个方法,使得相关时间大幅度减少。这个方法叫做逐次迭代自动标签法。在后面会介绍这个方法。
贴标签后的车牌数据如下图:

图7 在HasPlate文件夹下的图片
贴标签后的非车牌数据下图:

图8 在NoPlate文件夹下的图片
拥有了贴好标签的数据以后,下面的步骤是分组,也称之为divide过程。
3. divide (学习数据->分组数据)
分组这个过程是EasyPR1.1版新引入的方法。
在贴完标签以后,我拥有了车牌图片和非车牌图片共几千张。在我直接训练前,不急。先拿出30%的数据,只用剩下的70%数据进行SVM模型的训练,训练好的模型再用这30%数据进行一个效果测试。这30%数据充当的作用就是一个评判数据测试集,称之为test data,另70%数据称之为train data。于是一个完整的learn data被分为了train data和test data。
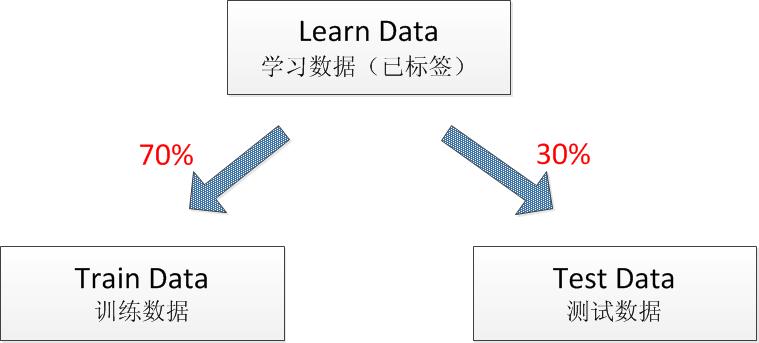
图9 数据分组过程
在EasyPR1.0版是没有test data概念的,所有数据都输入训练,然后直接在原始的数据上进行测试。直接在原始的数据集上测试与单独划分出30%的数据测试效果究竟有多少不同?
事实上,我们训练出模型的根本目的是为了对未知的,新的数据进行预测与判断。
当使用训练的数据进行测试时,由于模型已经考虑到了训练数据的特征,因此很难将这个测试效果推广到其他未知数据上。如果使用单独的测试集进行验证,由于测试数据集跟模型的生成没有关联,因此可以很好的反映出模型推广到其他场景下的效果。这个过程就可以简单描述为你不可以拿你给学生的复习提纲卷去考学生,而是应该出一份考察知识点一样,但题目不一样的卷子。前者的方式无法区分出真正学会的人和死记硬背的人,而后者就能有效地反映出哪些人才是真正“学会”的。
在divide的过程中,注意无论在train data和test data中都要保持数据的标签,也就是说车牌数据仍然归到HasPlate文件夹,非车牌数据归到NoPlate文件夹。于是,车牌图片30%归到test data下面的hasplate文件夹,70%归到train data下面的hasplate文件夹,非车牌图片30%归到test data下面的noplate文件夹,70%归到train data下面的noplate文件夹。于是在文件夹train 和 test下面又有两个子文件夹,他们的结构树就是下图:
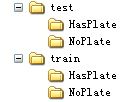
图10 分组后的文件树
divide数据结束以后,我们就可以进入真正的机器学习过程。也就是对数据的训练过程。
4. train (训练数据->模型)
模型在代码里的代表就是CvSVM类。在这一步中所要做的就是加载train data,然后用CvSVM类的train方法进行训练。这个步骤只针对的是上步中生成的总数据70%的训练数据。
具体来说,分为以下几个子步骤:
1) 加载待训练的车牌数据。见下面这段代码。

void getPlate(Mat& trainingImages, vector<int>& trainingLabels) { char * filePath = "train/data/plate_detect_svm/HasPlate/HasPlate"; vector<string> files; getFiles(filePath, files ); int size = files.size(); if (0 == size) cout << "No File Found in train HasPlate!" << endl; for (int i = 0;i < size;i++) { cout << files[i].c_str() << endl; Mat img = imread(files[i].c_str()); img= img.reshape(1, 1); trainingImages.push_back(img); trainingLabels.push_back(1); } }View Code
注意看,车牌图像我存储在的是一个vector<Mat>中,而标签数据我存储在的是一个vector<int>中。我将train/HasPlate中的图像依次取出来,存入vector<Mat>。每存入一个图像,同时也往vector<int>中存入一个int值1,也就是说图像和标签分别存在不同的vector对象里,但是保持一一对应的关系。
2) 加载待训练的非车牌数据,见下面这段代码中的函数。基本内容与加载车牌数据类似,不同之处在于文件夹是train/NoPlate,并且我往vector<int>中存入的是int值0,代表无车牌。
void getNoPlate(Mat& trainingImages, vector<int>& trainingLabels) { char * filePath = "train/data/plate_detect_svm/NoPlate/NoPlate"; vector<string> files; getFiles(filePath, files ); int size = files.size(); if (0 == size) cout << "No File Found in train NoPlate!" << endl; for (int i = 0;i < size;i++) { cout << files[i].c_str() << endl; Mat img = imread(files[i].c_str()); img= img.reshape(1, 1); trainingImages.push_back(img); trainingLabels.push_back(0); } }View Code
3) 将两者合并。目前拥有了两个vector<Mat>和两个vector<int>。将代表车牌图片和非车牌图片数据的两个vector<Mat>组成一个新的Mat--trainingData,而代表车牌图片与非车牌图片标签的两个vector<int>组成另一个Mat--classes。接着做一些数据类型的调整,以让其符合svm训练函数train的要求。这些做完后,数据的准备工作基本结束,下面就是参数配置的工作。
Mat classes;//(numPlates+numNoPlates, 1, CV_32FC1); Mat trainingData;//(numPlates+numNoPlates, imageWidth*imageHeight, CV_32FC1 ); Mat trainingImages; vector<int> trainingLabels; getPlate(trainingImages, trainingLabels); getNoPlate(trainingImages, trainingLabels); Mat(trainingImages).copyTo(trainingData); trainingData.convertTo(trainingData, CV_32FC1); Mat(trainingLabels).copyTo(classes);View Code
4) 配置SVM模型的训练参数。SVM模型的训练需要一个CvSVMParams的对象,这个类是SVM模型中训练对象的参数的组合,如何给这里的参数赋值,是很有讲究的一个工作。注意,这里是SVM训练的核心内容,也是最能体现一个机器学习专家和新手区别的地方。机器学习最后模型的效果差异有很大因素取决与模型训练时的参数,尤其是SVM,有非常多的参数供你配置(见下面的代码)。参数众多是一个问题,更为显著的是,机器学习模型中参数的一点微调都可能带来最终结果的巨大差异。
CvSVMParams SVM_params; SVM_params.svm_type = CvSVM::C_SVC; SVM_params.kernel_type = CvSVM::LINEAR; //CvSVM::LINEAR; SVM_params.degree = 0; SVM_params.gamma = 1; SVM_params.coef0 = 0; SVM_params.C = 1; SVM_params.nu = 0; SVM_params.p = 0; SVM_params.term_crit = cvTermCriteria(CV_TERMCRIT_ITER, 1000, 0.01);
opencv官网文档对CvSVMParams类的各个参数有一个详细的解释。如果你上过SVM课程的理论部分,你可能对这些参数的意思能搞的明白。但在这里,我们可以不去管参数的含义,因为我们有更好的方法去解决这个问题。

图11 SVM各参数的作用
这个原因在于:EasyPR1.0使用的是liner核,也称之为线型核,因此degree和gamma还有coef0三个参数没有作用。同时,在这里SVM模型用作的问题是分类问题,那么nu和p两个参数也没有影响。最后唯一能影响的参数只有Cvalue。到了EasyPR1.1版本以后,默认使用的是RBF核,因此需要调整的参数多了一个gamma。
以上参数的选择都可以用自动训练(train_auto)的方法去解决,在下面的SVM调优部分会具体介绍train_auto。
5) 开始训练。OK!数据载入完毕,参数配置结束,一切准备就绪,下面就是交给opencv的时间。我们只要将前面的 trainingData,classes,以及CvSVMParams的对象SVM_params交给CvSVM类的train函数就可以。另外,直接使用CvSVM的构造函数,也可以完成训练过程。例如下面这行代码:
CvSVM svm(trainingData, classes, Mat(), Mat(), SVM_params);
训练开始后,慢慢等一会。机器学习中数据训练的计算量往往是非常大的,即便现代计算机也要运行很长时间。具体的时间取决于你训练的数据量的大小以及模型的复杂度。在我的2.0GHz的机器上,训练1000条数据的SVM模型的时间大约在1分钟左右。
训练完成以后,我们就可以用CvSVM类的对象svm去进行预测了。如果我们仅仅需要这个模型,现在可以把它存到xml文件里,留待下次使用:
FileStorage fsTo("train/svm.xml", cv::FileStorage::WRITE); svm.write(*fsTo, "svm");
5. test (测试数据->评判指标)
记得我们还有30%的测试数据了么?现在是使用它们的时候了。将这些数据以及它们的标签加载如内存,这个过程与加载训练数据的过程是一样的。接着使用我们训练好的SVM模型去判断这些图片。
下面的步骤是对我们的模型做指标评判的过程。首先,测试数据是有标签的数据,这意味着我们知道每张图片是车牌还是不是车牌。另外,用新生成的svm模型对数据进行判断,也会生成一个标签,叫做“预测标签”。“预测标签”与“标签”一般是存在误差的,这也就是模型的误差。这种误差有两种情况:1.这副图片是真的车牌,但是svm模型判断它是“非车牌”;2.这幅图片不是车牌,但svm模型判断它是“车牌”。无疑,这两种情况都属于svm模型判断失误的情况。我们需要设计出来两个指标,来分别评测这两种失误情况发生的概率。这两个指标就是下面要说的“准确率”(precision)和“查全率”(recall)。
准确率是统计在我已经预测为车牌的图片中,真正车牌数据所占的比例。假设我们用ptrue_rtrue表示预测(p)为车牌并且实际(r)为车牌的数量,而用ptrue_rfalse表示实际不为车牌的数量。
准确率的计算公式是:
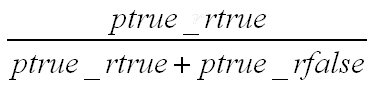
图12 precise 准确率
查全率是统计真正的车牌图片中,我预测为车牌的图片所占的比例。同上,我们用ptrue_rtrue表示预测与实际都为车牌的数量。用pfalse_rtrue表示实际为车牌,但我预测为非车牌的数量。
查全率的计算公式是:
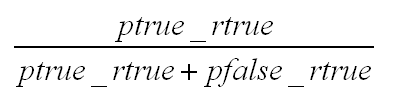
图13 recall 查全率
recall的公式与precision公式唯一的区别在于右下角。precision是ptrue_rfalse,代表预测为车牌但实际不是的数量;而recall是pfalse_rtrue,代表预测是非车牌但其实是车牌的数量。
简单来说,precision指标的期望含义就是要“查的准”,recall的期望含义就是“不要漏”。查全率还有一个翻译叫做“召回率”。但很明显,召回这个词没有反映出查全率所体现出的不要漏的含义。
值得说明的是,precise和recall这两个值自然是越高越好。但是如果一个高,一个低的话效果会如何,如何跟两个都中等的情况进行比较?为了能够数字化这种比较。机器学习界又引入了FScore这个数值。当precise和recall两者中任一者较高,而另一者较低是,FScore都会较低。两者中等的情况下Fscore表现比一高一低要好。当两者都很高时,FScore会很高。
FScore的计算公式如下图:
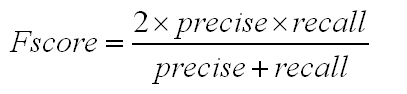
图14 Fscore计算公式
模型测试以及评价指标是EasyPR1.1中新增的功能。在svm_train.cpp的最下面可以看到这三个指标的计算过程。
训练心得
通过以上5个步骤,我们就完成了模型的准备,训练,测试的全部过程。下面,说一说过程中的几点心得。
1. 完善EasyPR的plateLocate功能
在1.1版本中的EasyPR的车牌定位模块仍然不够完善。如果你的所有的图片符合某种通用的模式,参照前面的车牌定位的几篇教程,以及使用EasyPR新增的Debug模式,你可以将EasyPR的plateLocate模块改造为适合你的情况。于是,你就可以利用EasyPR为你制造大量的学习数据。通过原始数据的输入,然后通过plateLocate进行定位,再使用EasyPR已有的车牌判断模块进行图片的分类,于是你就可以得到一个基本分好类的学习数据。下面所需要做的就是人工核对,确认一下,保证每张图片的标签是正确的,然后再输入模型进行训练。
2. 使用“逐次迭代自动标签法”。
上面讨论的贴标签方法是在EasyPR已经提供了一个训练好的模型的情况下。如果一开始手上任何模型都没有,该怎么办?假设目前手里有成千上万个通过定位出来的各种候选车牌,手工一个个贴标签的话,岂不会让人累吐血?在前文中说过,我在一开始贴标签过程中碰到了这个问题,在不断被折磨与痛苦中,我发现了一个好方法,大幅度减轻了这整个工作的痛苦性。
当然,这个方法很简单。我如果说出来你一定也不觉得有什么奇妙的。但是如果在你准备对1000张图片进行手工贴标签时,相信我,使用这个方法会让你最后的时间节省一半。如果你需要雇10个人来贴标签的话,那么用了这个方法,可能你最后一个人都不用雇。
这个方法被我称为“逐次迭代自动标签法”。
方法核心很简单。就是假设你有3000张未分类的图片。你从中选出1%,也就是30张出来,手工给它们每个图片进行分类工作。好的,如今你有了30张贴好标签的数据了,下步你把它直接输入到SVM模型中训练,获得了一个简单粗旷的模型。之后,你从图片集中再取出3%的图片,也就是90张,然后用刚训练好的模型对这些图片进行预测,根据预测结果将它们自动分到hasplate和noplate文件夹下面。分完以后,你到这两个文件夹下面,看看哪些是预测错的,把hasplate里预测错的移动到noplate里,反之,把noplate里预测错的移动到hasplate里。
接着,你把一开始手工分类好的那30张图片,结合调整分类的90张图片,总共120张图片再输入svm模型中进行训练。于是你获得一个比最开始粗旷模型更精准点的模型。然后,你从3000张图片中再取出6%的图片来,用这个模型再对它们进行预测,分类....
以上反复。你每训练出一个新模型,用它来预测后面更多的数据,然后自动分类。这样做最大的好处就是你只需要移动那些被分类错误的图片。其他的图片已经被正 确的归类了。注意,在整个过程中,你每次只需要对新拿出的数据进行人工确认,因为前面的数据已经分好类了。因此,你最好使用两个文件夹,一个是已经分好类 的数据,另一个是自动分类数据,需要手工确认的。这样两者不容易乱。
每次从未标签的原始数据库中取出的数据不要多,最好不要超过上次数据的两倍。这样可以保证你的模型的准确率稳步上升。如果想一口吃个大胖子,例如用30张图片训练出的模型,去预测1000张数据,那最后结果跟你手工分类没有任何区别了。
整个方法的原理很简单,就是不断迭代循环细化的思想。跟软件工程中迭代开发过程有异曲同工之妙。你只要理解了其原理,很容易就可以复用在任何其他机器学习模型的训练中,从而大幅度(或者部分)减轻机器学习过程中贴标签的巨大负担。
回到一个核心问题,对于开发者而言,什么样的方法才是自己实现一个svm.xml的最好方法。有以下几种选择。
1.你使用EasyPR提供的svm.xml,这个方式等同于你没有训练,那么EasyPR识别的效率取决于你的环境与EasyPR的匹配度。运气好的话,这个效果也会不错。但如果你的环境下车牌跟EasyPR默认的不一样。那么可能就会有点问题。
2.使用EasyPR提供的训练数据,例如train/data文件下的数据,这样生成的效果等同于第一步的,不过你可以调整参数,试试看模型的表现会不会更好一点。
3.使用自己的数据进行训练。这个方法的适应性最好。首先你得准备你原始的数据,并且写一个处理方法,能够将原始数据转化为学习数据。下面你调用EasyPR的PlateLocate方法进行处理,将候选车牌图片从原图片截取出来。你可以使用逐次迭代自动标签思想,使用EasyPR已有的svm模型对这些候选图片进行预标签。然后再进行肉眼确认和手工调整,以生成标准的贴好标签的数据。后面的步骤就可以按照分组,训练,测试等过程顺次走下去。如果你使用了EasyPR1.1版本,后面的这几个过程已经帮你实现好代码了,你甚至可以直接在命令行选择操作。
以上就是SVM模型训练的部分,通过这个步骤的学习,你知道如何通过已有的数据去训练出一个自己的模型。下面的部分,是对这个训练过程的一个思考,讨论通过何种方法可以改善我最后模型的效果。
三.SVM调优
SVM调优部分,是通过对SVM的原理进行了解,并运用机器学习的一些调优策略进行优化的步骤。
在这个部分里,最好要懂一点机器学习的知识。同时,本部分也会讲的尽量通俗易懂,让人不会有理解上的负担。在EasyPR1.0版本中,SVM模型的代码完全参考了mastering opencv书里的实现思路。从1.1版本开始,EasyPR对车牌判断模块进行了优化,使得模型最后的效果有了较大的改善。
具体说来,本部分主要包括如下几个子部分:1.RBF核;2.参数调优;3.特征提取;4.接口函数;5.自动化。
下面分别对这几个子部分展开介绍。
1.RBF核
SVM中最关键的技巧是核技巧。“核”其实是一个函数,通过一些转换规则把低维的数据映射为高维的数据。在机器学习里,数据跟向量是等同的意思。例如,一个 [174, 72]表示人的身高与体重的数据就是一个两维的向量。在这里,维度代表的是向量的长度。(务必要区分“维度”这个词在不同语境下的含义,有的时候我们会说向量是一维的,矩阵是二维的,这种说法针对的是数据展开的层次。机器学习里讲的维度代表的是向量的长度,与前者不同)
简单来说,低维空间到高维空间映射带来的好处就是可以利用高维空间的线型切割模拟低维空间的非线性分类效果。也就是说,SVM模型其实只能做线型分类,但是在线型分类前,它可以通过核技巧把数据映射到高维,然后在高维空间进行线型切割。高维空间的线型切割完后在低维空间中最后看到的效果就是划出了一条复杂的分线型分类界限。从这点来看,SVM并没有完成真正的非线性分类,而是通过其它方式达到了类似目的,可谓“曲径通幽”。
SVM模型总共可以支持多少种核呢。根据官方文档,支持的核类型有以下几种:
liner核和rbf核是所有核中应用最广泛的。
liner核,虽然名称带核,但它其实是无核模型,也就是没有使用核函数对数据进行转换。因此,它的分类效果仅仅比逻辑回归好一点。在EasyPR1.0版中,我们的SVM模型应用的是liner核。我们用的是图像的全部像素作为特征。
rbf核,会将输入数据的特征维数进行一个维度转换,具体会转换为多少维?这个等于你输入的训练量。假设你有500张图片,rbf核会把每张图片的数据转 换为500维的。如果你有1000张图片,rbf核会把每幅图片的特征转到1000维。这么说来,随着你输入训练数据量的增长,数据的维数越多。更方便在高维空间下的分类效果,因此最后模型效果表现较好。
既然选择SVM作为模型,而且SVM中核心的关键技巧是核函数,那么理应使用带核的函数模型,充分利用数据高维化的好处,利用高维的线型分类带来低维空间下的非线性分类效果。但是,rbf核的使用是需要条件的。
当你的数据量很大,但是每个数据量的维度一般时,才适合用rbf核。相反,当你的数据量不多,但是每个数据量的维数都很大时,适合用线型核。
在EasyPR1.0版中,我们用的是图像的全部像素作为特征,那么根据车牌图像的136×36的大小来看的话,就是4896维的数据,再加上我们输入的 是彩色图像,也就是说有R,G,B三个通道,那么数量还要乘以3,也就是14688个维度。这是一个非常庞大的数据量,你可以把每幅图片的数据理解为长度 为14688的向量。这个时候,每个数据的维度很大,而数据的总数很少,如果用rbf核的话,相反效果反而不如无核。
在EasyPR1.1版本时,输入训练的数据有3000张图片,每个数据的特征改用直方统计,共有172个维度。这个场景下,如果用rbf核的话,就会将每个数据的维度转化为与数据总数一样的数量,也就是3000的维度,可以充分利用数据高维化后的好处。
因此可以看出,为了让EasyPR新版使用rbf核技巧,我们给训练数据做了增加,扩充了两倍的数据,同时,减小了每个数据的维度。以此满足了rbf核的使用条件。通过使用rbf核来训练,充分发挥了非线性模型分类的优势,因此带来了较好的分类效果。
但是,使用rbf核也有一个问题,那就是参数设置的问题。在rbf训练的过程中,参数的选择会显著的影响最后rbf核训练出模型的效果。因此必须对参数进行最优选择。
2.参数调优
传统的参数调优方法是人手完成的。机器学习工程师观察训练出的模型与参数的对应关系,不断调整,寻找最优的参数。由于机器学习工程师大部分时间在调整模型的参数,也有了“机器学习就是调参”这个说法。
幸好,opencv的svm方法中提供了一个自动训练的方法。也就是由opencv帮你,不断改变参数,训练模型,测试模型,最后选择模型效果最好的那些参数。整个过程是全自动的,完全不需要你参与,你只需要输入你需要调整参数的参数类型,以及每次参数调整的步长即可。
现在有个问题,如何验证svm参数的效果?你可能会说,使用训练集以外的那30%测试集啊。但事实上,机器学习模型中专门有一个数据集,是用来验证参数效果的。也就是交叉验证集(cross validation set,简称validate data) 这个概念。
validate data就是专门从train data中取出一部分数据,用这部分数据来验证参数调整的效果。比方说现在有70%的训练数据,从中取出20%的数据,剩下50%数据用来训练,再用训练出来的模型在20%数据上进行测试。这20%的数据就叫做validate data。真正拿来训练的数据仅仅只是50%的数据。
正如上面把数据划分为test data和train data的理由一样。为了验证参数在新数据上的推广性,我们不能用一个训练数据集,所以我们要把训练数据集再细分为train data和validate data。在train data上训练,然后在validate data上测试参数的效果。所以说,在一个更一般的机器学习场景中,机器学习工程师会把数据分为train data,validate data,以及test data。在train data上训练模型,用validate data测试参数,最后用test data测试模型和参数的整体表现。
说了这么多,那么,大家可能要问,是不是还缺少一个数据集,需要再划分出来一个validate data吧。但是答案是No。opencv的train_auto函数帮你完成了所有工作,你只需要告诉它,你需要划分多少个子分组,以及validate data所占的比例。然后train_auto函数会自动帮你从你输入的train data中划分出一部分的validate data,然后自动测试,选择表现效果最好的参数。
感谢train_auto函数!既帮我们划分了参数验证的数据集,还帮我们一步步调整参数,最后选择效果最好的那个参数,可谓是节省了调优过程中80%的工作。
train_auto函数的调用代码如下:
svm.train_auto(trainingData, classes, Mat(), Mat(), SVM_params, 10, CvSVM::get_default_grid(CvSVM::C), CvSVM::get_default_grid(CvSVM::GAMMA), CvSVM::get_default_grid(CvSVM::P), CvSVM::get_default_grid(CvSVM::NU), CvSVM::get_default_grid(CvSVM::COEF), CvSVM::get_default_grid(CvSVM::DEGREE), true);
你唯一需要做的就是泡杯茶,翻翻书,然后慢慢等待这计算机帮你处理好所有事情(时间较长,因为每次调整参数又得重新训练一次)。作者最近的一次训练的耗时为1个半小时)。
训练完毕后,看看模型和参数在test data上的表现把。99%的precise和98%的recall。非常棒,比任何一次手工配的效果都好。
3.特征提取
在rbf核介绍时提到过,输入数据的特征的维度现在是172,那么这个数字是如何计算出来的?现在的特征用的是直方统计函数,也就是先把图像二值化,然后统计图像中一行元素中1的数目,由于输入图像有36行,因此有36个值,再统计图像中每一列中1的数目,图像有136列,因此有136个值,两者相加正好等于172。新的输入数据的特征提取函数就是下面的代码:
// ! EasyPR的getFeatures回调函数 // !本函数是获取垂直和水平的直方图图值 void getHistogramFeatures(const Mat& image, Mat& features) { Mat grayImage; cvtColor(image, grayImage, CV_RGB2GRAY); Mat img_threshold; threshold(grayImage, img_threshold, 0, 255, CV_THRESH_OTSU+CV_THRESH_BINARY); features = getTheFeatures(img_threshold); }
我们输入数据的特征不再是全部的三原色的像素值了,而是抽取过的一些特征。从原始的图像到抽取后的特征的过程就被称为特征提取的过程。在1.0版中没有特征提取的概念,是直接把图像中全部像素作为特征的。这要感谢群里的“如果有一天”同学,他坚持认为全部像素的输入是最低级的做法,认为用特征提取后的效果会好多。我问大概能到多少准确率,当时的准确率有92%,我以为已经很高了,结果他说能到99%。在半信半疑中我尝试了,果真如他所说,结合了rbf核与新特征训练的模型达到的precise在99%左右,而且recall也有98%,这真是个令人咋舌并且非常惊喜的成绩。
“如果有一天”建议用的是SFIT特征提取或者HOG特征提取,由于时间原因,这两者我没有实现,但是把函数留在了那里。留待以后有时间完成。在这个过程中,我充分体会到了开源的力量,如果不是把软件开源,如果不是有这么多优秀的大家一起讨论,这样的思路与改善是不可能出现的。
4.接口函数
由于有SIFT以及HOG等特征没有实现,而且未来有可能会有更多有效的特征函数出现。因此我把特征函数抽象为借口。使用回调函数的思路实现。所有回调函数的代码都在feature.cpp中,开发者可以实现自己的回调函数,并把它赋值给EasyPR中的某个函数指针,从而实现自定义的特征提取。也许你们会有更多更好的特征的想法与创意。
关于特征其实有更多的思考,原始的SVM模型的输入是图像的全部像素,正如人类在小时候通过图像识别各种事物的过程。后来SVM模型的输入是经过抽取的特 征。正如随着人类接触的事物越来越多,会发现单凭图像越来越难区分一些非常相似的东西,于是学会了总结特征。例如太阳就是圆的,黄色,在天空等,可以凭借 这些特征就进行区分和判断。
从本质上说,特征是区分事物的关键特性。这些特性,一定是从某些维度去看待的。例如,苹果和梨子,一个是绿色,一个是黄色,这就是颜色的维度;鱼和鸟,一个在水里,一个在空中,这是位置的区分,也就是空间的维度。特征,是许多维度中最有区分意义的维度。传统cangku.html" target="_blank">数据仓库中的OLAP,也称为多维分析,提供了人类从多个维度观察,比较的能力。通过人类的观察比较,从多个维度中挑选出来的维度,就是要分析目标的特征。从这点来看,机器学习与多维分析有了关联。多维分析提供了选择特征的能力。而机器学习可以根据这些特征进行建模。
机器学习界也有很多算法,专门是用来从数据中抽取特征信息的。例如传统的PCA(主成分分析)算法以及最近流行的深度学习中的 AutoEncoder(自动编码机)技术。这些算法的主要功能就是在数据中学习出最能够明显区分数据的特征,从而提升后续的机器学习分类算法的效果。
说一个特征学习的案例。作者买车时,经常会把大众的两款车--迈腾与帕萨特给弄混,因为两者实在太像了。大家可以到网上去搜一下这两车的图片。如果不依赖后排的文字,光靠外形实在难以将两车区分开来(虽然从生产商来说,前者是一汽大众生产的,产地在长春,后者是上海大众生产的,产地在上海。两个不同的公司,南北两个地方,相差了十万八千里)。后来我通过仔细观察,终于发现了一个明显区分两辆车的特征,后来我再也没有认错过。这个特征就是:迈腾的前脸有四条银杠,而帕萨特只有三条,迈腾比帕萨特多一条银杠。可以这么说,就是这么一条银杠,分割了北和南两个地方生产的汽车。

图15 一条银杠,分割了“北”和“南”
在这里区分的过程,我是通过不断学习与研究才发现了这些区分的特征,这充分说明了事物的特征也是可以被学习的。如果让机器学习中的特征选择方法PCA和AutoEncoder来分析的话,按理来说它们也应该找出这条银杠,否则它们就无法做到对这两类最有效的分类与判断。如果没有找到的话,证明我们目前的特征选择算法还有很多的改进空间(与这个案例类似的还有大众的另两款车,高尔夫和Polo。它们两的区分也是用同样的道理。相比迈腾和帕萨特,高尔夫和Polo价格差别的更大,所以区分的特征也更有价值)。
5.自动化
最后我想简单谈一下EasyPR1.1新增的自动化训练功能与命令行。大家可能看到第二部分介绍SVM训练时我将过程分成了5个步骤。事实上,这些步骤中的很多过程是可以模块化的。一开始的时候我写一些不相关的代码函数,帮我处理各种需要解决的问题,例如数据的分组,打标签等等。但后来,我把思路理清后,我觉得这几个步骤中很多的代码都可以通用。于是我把一些步骤模块化出来,形成通用的函数,并写了一个命令行界面去调用它们。在你运行EasyPR1.1版后,在你看到的第一个命令行界面选择“3.SVM训练过程”,你就可以看到这些全部的命令。
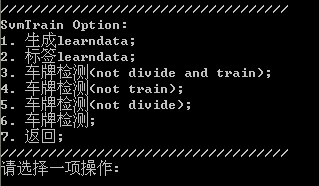
图16 svm训练命令行
这里的命令主要有6个部分。第一个部分是最可能需要修改代码的地方,因为每个人的原始数据(raw data)都是不一样的,因此你需要在data_prepare.cpp中找到这个函数,改写成适应你格式的代码。接下来的第二个部分以后的功能基本都可以复用。例如自动贴标签(注意贴完以后要人工核对一下)。
第三个到第六部分功能类似。如果你的数据还没分组,那么你执行3以后,系统自动帮你分组,然后训练,再测试验证。第四个命令行省略了分组过程。第五个命令行部分省略训练过程。第六个命令行省略了前面所有过程,只做最后模型的测试部分。
让我们回顾一下SVM调优的五个思路。第一部分是rbf核,也就是模型选择层次,根据你的实际环境选择最合适的模型。第二部分是参数调优,也就是参数优化层次,这部分的参数最好通过一个验证集来确认,也可以使用opencv自带的train_auto函数。第三部分是特征抽取部分,也就是特征甄选们,要能选择出最能反映数据本质区别的特征来。在这方面,pca以及深度学习技术中的autoencoder可能都会有所帮助。第四部分是通用接口部分,为了给优化留下空间,需要抽象出接口,方便后续的改进与对比。第五部分是自动化部分,为了节省时间,将大量可以自动化处理的功能模块化出来,然后提供一些方便的操作界面。前三部分是从机器学习的效果来提高,后两部分是从软件工程的层面去优化。
总结起来,就是模型,参数,特征,接口,模块五个层面。通过这五个层面,可以有效的提高机器学习模型训练的效果与速度,从而降低机器学习工程实施的难度与提升相关的效率。当需要对机器学习模型进行调优的时候,我们可以从这五个层面去考虑。
后记
讲到这里,本次的SVM开发详解也算是结束了。相信通过这篇文档,以及作者的一些心得,会对你在SVM模型的开发上面带来一些帮助。下面的工作可以考虑把这些相关的方法与思路运用到其他领域,或着改善EasyPR目前已有的模型与算法。如果你找出了比目前更好实现的思路,并且你愿意跟我们分享,那我们是非常欢迎的。
EasyPR1.1的版本发生了较大的变化。我为了让它拥有多人协作,众包开发的能力,想过很多办法。最后决定引入了GDTS(General Data Test Set,通用测试数据集,也就是新的image/general_test下的众多车牌图片)以及GDSL(General Data Share License,通用数据分享协议,image/GDSL.txt)。这些概念与协议的引入非常重要,可能会改变目前车牌识别与机器学习在国内学习研究的格局。在下期的EasyPR开发详解中我会重点介绍1.1版的新加入功能以及这两个概念和背后的思想,欢迎继续阅读。
上一篇还是第四篇,为什么本期SVM开发详解属于EasyPR开发的第六篇?事实上,对于目前的车牌定位模块我们团队觉得还有改进空间,所以第五篇的详解内容是留给改进后的车牌定位模块的。如果有车牌定位模块方面好的建议或者希望加入开源团队,欢迎跟我们团队联系(easypr_dev@163.com )。您也可以为中国的开源事业做出一份贡献。
版权说明:
本文中的所有文字,图片,代码的版权都是属于作者和博客园共同所有。欢迎转载,但是务必注明作者与出处。任何未经允许的剽窃以及爬虫抓取都属于侵权,作者和博客园保留所有权利。