? ? ? ?貌似每次写博客之前就得先说说自己又多久多久没有写过博客了,这次的博客距上次的已经过了快一年了,确实自制力不够,懒癌加拖延症患者伤不起。
? ? ? ? 咳咳,接下来进入正题:数据结构已经很让人头疼了,不过更让人头疼的还有hash。那么什么是hash?
?
全称:hash table
简写:HT
中文名:散列表
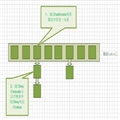
结构:hash table中的一个位置叫做一个槽(怎么就感觉像是个坑),注意了:一个槽里只能放一个数据,槽的数量姑且用M表示,则一个hash table中就有用0―M-1编号的M个槽(不同hash table的结构不同,其中有一种就是在这个名为“槽”的坑里再挖若干个坑,要不然装不下我们要装的东西)。
怎么用:这里又涉及到名为“散列函数”的东西(不用知道它具体是什么样的,因为它具有变色龙的性质,知道它是一个函数就好),我们利用这个散列函数(实际上就是通过一系列的计算),将我们要保存的数据放到那一个一个坑里去。那么问题来了,要是坑里已经放了一个数据了,新数据通过计算之后又是应该放在那个坑里的,放不下怎么办,这样上面说的坑里再挖坑就排上用场了 (当然不止这一种方法哦),这里,坑里再挖的坑由于需要有一定的灵活性,我们通常用链表来实现。
(当然不止这一种方法哦),这里,坑里再挖的坑由于需要有一定的灵活性,我们通常用链表来实现。
?
? ? ? ?通过以上简介,我们大概知道了hash table的大概情况了,接下来,上手了,代码来也~
?
class="java"> /**
* 存
* @param k
* @param v
*/
public boolean put(K k, V v) {
// 1.计算K的hash值
// 直接调用JDK给出的hashCode()方法来计算hash值
int hash = k.hashCode();
//将所有信息封装为一个Entry
Entry< K,V> temp=new Entry(k,v,hash);
if(setEntry(temp, container)){
// 大小加一
size++;
return true;
}
return false;
}
?
/**
* 取
* @param k
* @return
*/
public V get(K k) {
Entry< K, V> entry = null;
// 1.计算K的hash值
int hash = k.hashCode();
// 2.根据hash值找到下标
int index = indexFor(hash, container.length);
// 3.根据index找到链表
entry = container[index];
// 4.若链表为空,返回null
if (null == entry) {
return null;
}
// 5.若不为空,遍历链表,比较k是否相等,如果k相等,则返回该value
while (null != entry) {
if (k == entry.getKey()||entry.getKey().equals(k)) {
return entry.getValue();
}
entry = entry.getNext();
}
// 如果遍历完了不相等,则返回空
return null;
}
?
/**
*将指定的结点temp添加到指定的hash表table当中
* 添加时判断该结点是否已经存在
* 如果已经存在,返回false
* 添加成功返回true
* @param temp
* @param table
* @return
*/
private boolean setEntry(Entry< K,V> temp,Entry[] table){
// 根据hash值找到下标
int index = indexFor(temp.getHash(), table.length);
//根据下标找到对应元素
Entry< K, V> entry = table[index];
// 3.若存在
if (null != entry) {
// 3.1遍历整个链表,判断是否相等
while (null != entry) {
//判断相等的条件时应该注意,除了比较地址相同外,引用传递的相等用equals()方法比较
//相等则不存,返回false
if ((temp.getKey() == entry.getKey()||temp.getKey().equals(entry.getKey())) &&
temp.getHash() == entry.getHash()&&(temp.getValue()==entry.getValue()||temp.getValue().equals(entry.getValue()))) {
return false;
}
else if(temp.getKey() == entry.getKey() && temp.getValue() != entry.getValue()) {
entry.setValue(temp.getValue());
return true;
}
//不相等则比较下一个元素
else if (temp.getKey() != entry.getKey()) {
//到达队尾,中断循环
if(null==entry.getNext()){
break;
}
// 没有到达队尾,继续遍历下一个元素
entry = entry.getNext();
}
}
// 3.2当遍历到了队尾,如果都没有相同的元素,则将该元素挂在队尾
addEntry2Last(entry,temp);
return true;
}
// 4.若不存在,直接设置初始化元素
setFirstEntry(temp,index,table);
return true;
}
?
/**
* 扩容
* @param newSize 新的容器大小
*/
private void reSize(int newSize) {
// 1.声明新数组
Entry< K, V>[] newTable = new Entry[newSize];
max = (int) (newSize * LOAD_FACTOR);
// 2.复制已有元素,即遍历所有元素,每个元素再存一遍
for (int j = 0; j < container.length; j++) {
Entry< K, V> entry = container[j];
//因为每个数组元素其实为链表,所以…………
while (null != entry) {
setEntry(entry, newTable);
entry = entry.getNext();
}
}
// 3.改变指向
container = newTable;
}
?PS.扩容存在的意义:当一个槽里挖得坑太多了,总会有不能再挖的一天,这个时候我们就只能把槽的数量增加,当槽的数量增加之后,我们应该复制之前的所有元素,将其再遍历存一次。
?
最后的最后,各种数据结构增删查改的时间比较,省略。在下只附上hash表究竟有多快~
?
?