?
How to write UTF-8 file with fprintf in C++
http://stackoverflow.com/questions/10028750/how-to-write-utf-8-file-with-fprintf-in-c
?
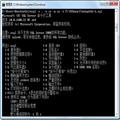
ou shouldn't need to set your locale or set any special modes on the file if you just want to use fprintf. You simply have to use UTF-8 encoded strings.
class="cpp" name="code">#include <cstdio>
#include <codecvt>
int main() {
std::wstring_convert<std::codecvt_utf8_utf16<wchar_t>,wchar_t> convert;
std::string utf8_string = convert.to_bytes(L"кошка 日本国");
if(FILE *f = fopen("tmp","w"))
fprintf(f,"%s\n",utf8_string.c_str());
}
?
Save the program as UTF-8 with signature or UTF-16 (i.e. don't use UTF-8 without signature, otherwise VS won't produce the right string literal). The file written by the program will contain the UTF-8 version of that string. Or you can do:
int main() {
if(FILE *f = fopen("tmp","w"))
fprintf(f,"%s\n","кошка 日本国");
}
?
In this case you must save the file as UTF-8?without?signature, because you want the compiler to think the source encoding is the same as the execution encoding... This is a bit of a hack that relies on the compiler's, IMO, broken behavior.
You can do basically the same thing with any of the other APIs for writing narrow characters to a file, but note that none of these methods work for writing UTF-8 to the Windows console. Because the C runtime and/or the console is a bit broken you can only write UTF-8 directly to the console by doing SetConsoleOutputCP(65001) and then using one of the?monospace, sans-serif; white-space: pre-wrap; background-color: #eff0f1;">puts?variety of function.
If you want to use wide characters instead of narrow characters then locale based methods and setting modes on file descriptors could come into play.
#include <cstdio>
#include <fcntl.h>
#include <io.h>
int main() {
if(FILE *f = fopen("tmp","w")) {
_setmode(_fileno(f), _O_U8TEXT);
fwprintf(f,L"%s\n",L"кошка 日本国");
}
}
?
#include <fstream>
#include <codecvt>
int main() {
if(auto f = std::wofstream("tmp")) {
f.imbue(std::locale(std::locale(),
new std::codecvt_utf8_utf16<wchar_t>)); // assumes wchar_t is UTF-16
f << L"кошка 日本国\n";
}
}
?
The first example uses wstring_convert from C++11, but any other method of obtaining a UTF-8 encoding works too, e.g. WideCharToMultiByte. The last example uses a C++11 codecvt facet for which there's not a built-in, pre-c++11 replacement. The other two examples don't use C++11.?
?
How to Read/Write UTF8 text files in C?
http://stackoverflow.com/questions/21737906/how-to-read-write-utf8-text-files-in-c
Instead of
fprintf(fout,"%c ",character);
?
use
fprintf(fout,"%c",character);
?
The second?fprintf()?does not contain a space after?%c?which is what was causing?out.txt?to display weird characters. The reason is that?fgetc()?is retrieving a single byte (the same thing as an ASCII character),?not?a UTF-8 character. Since UTF-8 is also ASCII compatible, it will write English characters to the file just fine.
putchar(character)?output the bytes sequentially without the extra space between every byte so the original UTF-8 sequence remained intact. To see what I'm talking about, try
while((character=fgetc(fin))!=EOF){
putchar(character);
printf(" "); // This mimics what you are doing when you write to out.txt
fprintf(fout,"%c ",character);
}
?
If you want to write UTF-8 characters with the space between them to out.txt, you would need to handle the variable length encoding of a UTF-8 character.
#include <stdio.h> #include <stdlib.h> /* The first byte of a UTF-8 character * indicates how many bytes are in * the character, so only check that */ int numberOfBytesInChar(unsigned char val) { if (val < 128) { return 1; } else if (val < 224) { return 2; } else if (val < 240) { return 3; } else { return 4; } } int main(){ FILE *fin; FILE *fout; int character; fin = fopen("in.txt", "r"); fout = fopen("out.txt","w"); while( (character = fgetc(fin)) != EOF) { for (int i = 0; i < numberOfBytesInChar((unsigned char)character) - 1; i++) { putchar(character); fprintf(fout, "%c", character); character = fgetc(fin); } putchar(character); printf(" "); fprintf(fout, "%c ", character); } fclose(fin); fclose(fout); printf("\nFile has been created...\n"); return 0; }
?