相比新的网络请求框架Volley真的很落后,一无是处吗,要知道Volley是由google官方推出的,虽然推出的时间很久了,但是其中依然有值得学习的地方。 从命名我们就能看出一些端倪,volley中文意为群射,齐射,即它适合通信频繁但是数据量不大的网络请求操作,至于为什么我们解读完源码就知道了。
回想下使用Volley的过程:比如请求一个网页的内容。
1. 创建RequestQueue对象
class="brush:java;gutter:true;"> RequestQueue mQueue = Volley.newRequestQueue(MyApplication.getInstance());
2. 先创建一个StringRequest对象
 logs_code_hide('2595f2e1-d100-427a-9c2c-9e5f11c0e3cb',event)" src="/Upload/Images/2017102723/2B1B950FA3DF188F.gif" alt="" />
logs_code_hide('2595f2e1-d100-427a-9c2c-9e5f11c0e3cb',event)" src="/Upload/Images/2017102723/2B1B950FA3DF188F.gif" alt="" />
private StringRequest stringRequest = new StringRequest( Request.Method.GET, "https://www.baidu.com", new Response.Listener<String>() { @Override public void onResponse(String response) { Log.d(TAG, "current thread :" + Thread.currentThread().getName()); // main thread ((TextView)findViewById(R.id.content)).setText(response); } }, new Response.ErrorListener() { @Override public void onErrorResponse(VolleyError error) { Log.d(TAG, "error :" + error.getMessage()); } } ) ;View Code
3. 将请求对象添加到mQueue中
mQueue.add(stringRequest);
如下流程描述请自行结合Volley中的源码阅读:
首先我们要构造RequestQueue, 其内部封装了缓存请求队列:
首先我们要构造RequestQueue, 其内部封装了缓存请求队列PriorityBlockingQueue<Request<?>> mCacheQueue 和网络请求队列 PriorityBlockingQueue<Request<?>> mNetworkQueue,同时也封装了一条缓存调度线程mCacheDispatcher和若干条网络请求调度线程 NetworkDispatcher[] mDispatchers,虽然RequestQueue的构造方法是public,但是我们还是调用Volley的newRequestQueue方法,因为在newRequestQueue方法有些重要的处理,比如设置DiskBasedCache的目录, 添加请求的User-agent,判断SDK的版本号,如果是2.3(API=9)以下则使用HttpClient, 如果是>=2.3的版本,则使用HttpUrlConnection,接着构建RequestQueue对象,并调用其start方法,创建并启动缓存调度线程和网络请求调度线程,目前的版本是1条缓存线程和4条网络请求线程。
接着查看RequestQueue.add的相关逻辑:
将构造的Request添加到RequestQueue中,即调用RequestQueue.add方法,这里会将请求先Add到一个Set集合中,即Set<Request<?>> mCurrentRequests中,然后判断是否禁用了缓存,如果禁用缓存则直接添加到mNetworkQueue中, 又因为NetworkDispatcher调度线程run方法中是while死循环,会一直取队列中的对象,故加入网络请求队列后,就相当于直接发起了网络请求。 而如果允许缓存,即Request.shouldCache返回true,则判断Map(Map<String,Queue<Request<?>> mWaitingRequests中是否有相同的请求,判断的标准就是请求的url,即request.getCacheKey()),如果mWaitingRequests中存在,则做提示处理,如果不存在则将请求添加到map中做记录,并执行mCacheQueue.add(request)
请求加入了CacheQueue队列中,则缓存调度线程就可以从队列中取出requeset做处理。查看缓存调度线程CacheDispatcher的run方法,while循环中的逻辑如下,先取出缓存queue中的请求对象request,根据请求的url得到cache, 判断cache中entry是否为空,如果为空则说明没有缓存,则将请求添加到mNetworkQueue中,mNetworkQueue.put(request), 交由网络请求线程处理。如果有缓存,判断缓存是否过期,如果过期则同上,如果缓存可用,则取出缓存中数据做解析并返回,即调用request.parseNetworkResponse方法,解析之后调用mDelivery.postResponse方法做结果的投递,这里就将操作从子线程转移到主线程了,具体是由mDelivery去处理切换的操作, mDelivery(具体实现类是ExecutorDelivery)内部封装了Handler和Executor,将最终解析出的结果投递到主线程handler.post(runnable), 此handler是主线程的handler,构造RequestQueue队列时创建了主线程的Handler对象了,代码如下:
public RequestQueue(Cache cache, Network network, int threadPoolSize) {
this(cache, network, threadPoolSize,
new ExecutorDelivery(new Handler(Looper.getMainLooper())));
}
5. 当请求添加到网络请求队列queue之后,在NetworkDispatcher的run方法中执行真正的网络请求,首先会判断线程是否退出了,或者request是否被取消了等逻辑,一切ok则执行mNetwork.performRequest(request),发起网络请求,然后解析结果,做缓存操作,派发解析结果到主线程等等
// 这里注意BlockingQueue的add offer put//// remove poll take peek等方法的区别
1.add 将元素插入queue中,如果立即可行且不违反容量规则返回true,如果当前没有可用空间,则抛出IllegalStateExecption
2.offer 与add方法类似,但是使用有限制容量的queue时,此方法通常优于add方法,后者可能可能无法插入元素,只是抛出一个异常
3. put 插入元素到queue尾部,如果空间不够,则等待空间变得可用
-----------------------------------------------------------------------------------------------------------------------------------
4. remove 移除元素,返回true如果queue总包含此元素
5.poll 获取并移除头部元素, E poll(), 如果queue为空,则返回null
6.take 获取并移除头部元素,如果没有则等待直到有头部元素变得可用, E take() throws InterruptedException。
7.peek 只是获取头部元素,并不做移除操作,如果queue为空,则返回null。
缓存执行流程
上面简要分析了请求执行的过程,那么Volley是如何实现缓存和获取缓存的呢,我们接着分析,试想我们第一次请求某个网络资源时,必然是没有缓存的,那么最终会走到网络调用线程NetworkDispatcher run方法中的逻辑,执行网络请求拿到NetworkResponse,然后解析networkResponse,即调用request的parseNetworkResponse得到Response对象,然后判断request是否允许缓存,如果需要缓存且response中的Cache.Entry即缓存对象不为空,则做缓存的操作。Cache.Entry对象cacheEntry什么时候被赋值的呢?就是在parseNetworkResponse返回Response对象的过程中,构造Response对象调用Response.success(result, HttpHeaderParser.parseCacheHeaders(response));, success函数的第二参数即为cacheEntry,查看parseCacheHeaders方法可以看到,entry中包含有data, etag,softTtl,lastModified,responseHeaders等数据。我们要缓存就是上边的cacheEntry,对应代码中的mCache.put(request.getCacheKey(), response.cacheEntry); 这里的mCache又是什么呢。查找mCache的源头又回到了Volley.newRequestQueue方法中,这里构建RequestQueue时传入了DiskBasedCache,那么看来mCache的具体实现类就是DiskBasedCache了。查看DiskBasedCache的源码,可以看到其默认缓存路径是/data/data/packagename/cache/volley/ , 默认的缓存大小为10M,其中最关键的就是put方法,put(String key, Entry entry) ,此方法首先会根据entry中data数组的长度判断是否能够缓存得下,也就是缓存后是否超过了设定的最大缓存容量值。具体在pruneINeed中做判断,如果超过最大值,则会按顺序依次从已缓存的文件中做caozuo.html" target="_blank">删除操作(PS:如何做到按顺序删除呢,因为在putEntry方法中将key和cacheHeader的信息存储在了LinkedHashMap中了, 所以删除的时候才能依次按照缓存的先后顺序删除,最先缓存的先被删除掉),直到缓存本次data不再超过最大值为止,然后创建一个File对象存储缓存数据,File的name是将Url字符串的前半部分的hashcode加上字符串后半部分的hashcode组合而成,具体请查看getFilenameForKey(String key)方法,然后构建FileOutputStream对象分别将CacheHeader信息和data数据部分信息写入文件,如果写入的过程中发生了异常,则会做删除文件的处理。至于读取的操作请查看get方法.
其实说了这么多,还是下面这张流程图的内容:
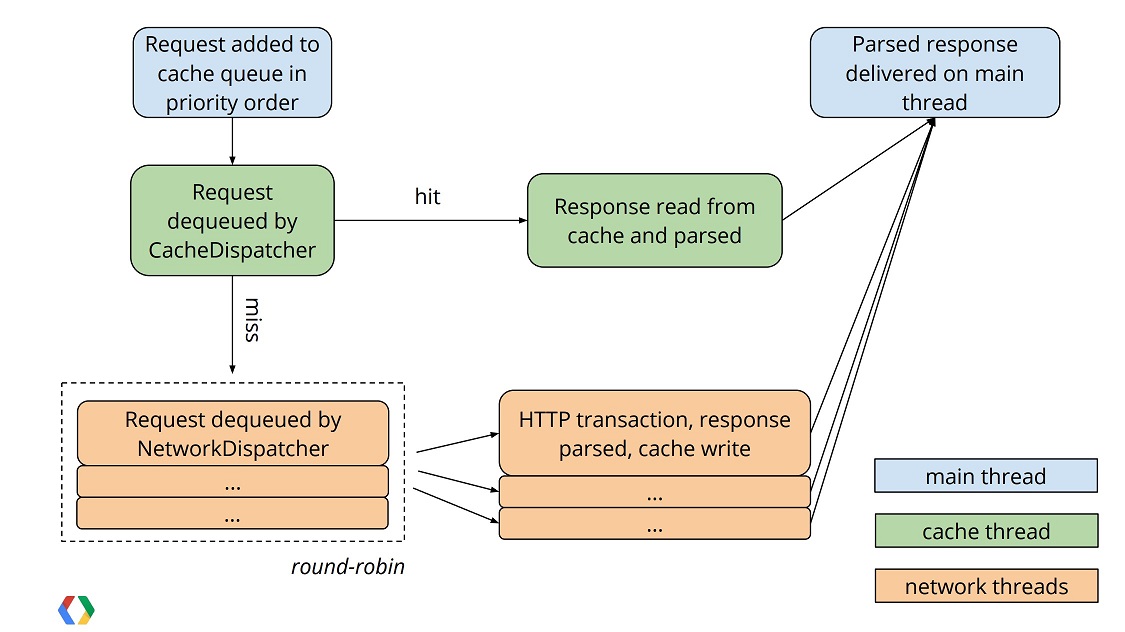
现在来做下问题总结:
1. 为什么说Volley不适合大文件的下载等操作,而是数据量小的通信网络场景?
因为从Volley的源码中我们可以发现,其内部执行网络请求的线程是固定数量4条线程,如果下载大文件可能就会导致线程被长时间占用,后面排队的Request可能长时间得不到执行,且在Volley内部有缓存机制,如果大文件也允许缓存,而设定的最大缓存容量值较小,则可能发生长时间的IO操作(因为可能超过最大容量而要做删除文件操作),导致应用性能下降。
2. Volley中的缓存调度线程和网络调用线程的run方法中是while死循环,什么时候退出,也就是缓存和网络调度线程什么时候结束工作?
其实在run方法的内部有相关逻辑, 比如NetworkDispatcher的run方法中,会捕获InterruptedException异常,在异常处理中判断mQuit的值,如果为true则直接返回。而调用Interrupt方法和设置mQuit值的处理就在NetworkDispatcher对应的quit() 方法中。
3. 可否将处理网络请求的线程改成线程池ThreadPoolExecutor?
可以改,但是即使改为线程池实现,性能可能也不会有提升,一方面对于手机cpu来说其核心数是有限的,如果线程池内的线程数配置的较大,则网络请求时可能导致线程的频繁的发生切换,而线程的切换是有开销的。
4. Volley可否加载较大的图片,比如十几M,几十M等?
因为Volley中解析完数据是要保存在byte[] data,中的,所以如果数据过大则有可能发生OOM异常。
5. 使用Volley时应该在哪里创建RequestQueue合适?
具体可以在自定义的Application中,主要是传递给newRequestQueue的Context应该使用ApplicationContext,这样可以避免可能发生的内存泄漏的情况,试想如果持有Activity的context那么Volley内部的工作没有做完则一直持有Activity,导致Activity无法释放,故在自定义的Apllication初始化一个全局的请求队列即可。
6. onResponse是在主线程中执行,但是返回结果后还需要做耗时操作怎么办?
从Volley的源码中我们能够知道派发器mDelivery的是ExecutorDelivery,其默认实现是传递主线程的handler的构造方法,而ExecutorDelivery的内部还有一个传递executor的构造方法,只要构建一个的executor,在new RequestQueue时,让 mDelivery = new ExecutorDelivery(executor), 那么onResponse最终就在executor的线程中执行, 不再是主线程了。
7. Volley有什么优缺点。
优点:
还是那句: 适合网络通信频繁,但是通信数据量不大的请求,不适合大文件的下载。
可以缓存http请求,过滤重复请求(一般网络请求框架也都支持)
支持请求的优先级
支持取消请求的API,可以取消单个请求,也可以设置取消请求的范围域
基于接口的设计,使扩展相对容易(比如写一个XMLRequest类 继承Request,实现onResponse方法和parseNetworkResponse方法)
缺点:
对于文件的上传和下载支持的不好
与Apache的Httpclient 和 HttpUrlConnection耦合较紧密
Android 6.0系统移除对HttpClient的支持,所以要使用Volley,需要配置org.apache.http.legacy.jar的引用
对http的支持不够完善。
待补充。。。