前几天的时候,在某一QQ群看到一条消息“XXX酒店开房XXXBTXX迅雷BT下载”,当时是一目十行的心态浏览,目光掠过时,第一反应时我邪恶了~以为是XX种子(你懂的~),所以并不感兴趣,呵呵.... 直到又回到博客园逛时,看到一篇最多评论的文章:
看看多线程的效率有多差劲! - 张浩华 - 博客园
http://www.cnblogs.com/zhhh/p/3385751.html
于是点击进去了。这时,我才回想起来,当时是自己邪恶想多了...... 原来是2000w条开房数据记录的数据库,浏览了文章后,我表示对这2000w感兴趣了!于是,就催生了此文。
看了上面提到的那文章,我决定也要玩一玩,不过那园友有点儿“懒”了,没有提供数据库以及Demo下载。好吧,这时候我们要发挥搜索本领了,几经搜索,最后是Google帮上的忙(百度搜索到的链接很多都已经被和谐了~)。 (温馨提示:近来上级严查水表,各位传播东西需小心~)。
一个小时过去了,1.7GB的压缩文件终于下载完成:
class="brush:csharp;gutter:true;">C:\[fuliba.net]某酒店2000W数据(解压密码:sjisauisa是就数据8很舒适好sjjss).rar 文件大小:1834815332字节 创建日期:2013年10月24日 15:38:55 哈希值(MD5):091AAC2B45D76CE1CD4248E7FFF1C00E
解压后,约8GB多。
面对这千万条数据级别的数据库文件,先来看一看我的本机配置信息:

1 操作系统名称 Microsoft Windows 7 Ultimate 2 操作系统核心(Kernel)类型 Multiprocessor Free (32-bit) 3 4 Microsoft SQL Server 2008R2 5 Microsoft SQL Server Management Studio 10.50.1600.1 6 Microsoft Analysis Services Client Tools 10.50.1600.1 7 Microsoft Data Access Components (MDAC) 6.1.7601.17514 8 Microsoft MSXML 3.0 5.0 6.0 9 Microsoft Internet Explorer 9.10.9200.16686 10 Microsoft .NET Framework 2.0.50727.5472 11 Operating System 6.1.7601 12 13 硬件概要 14 15 CPU: 英特尔 Core i3-380M (双核) 16 主板: 方正 R410CP (英特尔 HM55 (IbexPeak-M DH)) 17 内存: 6 GBytes 18 显卡: ATI/AMD Mobility Radeon HD 5450/5470 (PARK PRO/XT GL) 19 硬盘: 东芝 MK3265GSX 20 21 22 处理器信息 23 24 处理器: Intel(R) Core(TM) i3 CPU M 380 @ 2.53GHz 25 运行速度: 2533.3 MHz 26 核心/线程: 双核, 四线程 27 核心代号: Arrandale SV 28 功耗: 25.0 W 29 插座: Socket G1 (rPGA988A) 30 一级缓存: 指令: 2 x 32 KB, 数据: 2 x 32 KBytes 31 二级缓存: 集成: 2 x 256 KB 32 三级缓存: 3 MB 33 特性: MMX SSE SSE-2 SSE-3 SSSE-3 SSE4.1 SSE4.2 EMT64 VT EIST TM1 TM2 34 35 主板信息 36 37 主板厂商: 方正 38 主板型号: 方正 R410CP 39 芯片组: 英特尔 HM55 (IbexPeak-M DH) 40 主板插槽: 2xPCI Express x1, 6xPCI Express x2, 1xPCI Express x16 41 USB支持: v2.0 42 PCI-E支持: v2.0 43 BIOS版本: V1.12 44 BIOS日期: 12/21/2010 45 46 内存信息(总计:6 GBytes) 47 48 内存条1: 49 内存大小: 2048 MB 50 内存类型: DDR3 SDRAM 51 制造商: 三星 52 制造日期: 2010年第39周 53 54 内存条2: 55 内存大小: 4096 MB 56 内存类型: DDR3 SDRAM 57 制造商: 三星 58 制造日期: 2012年第1周 59 60 显卡信息 61 62 显卡芯片: ATI/AMD Mobility Radeon HD 5450/5470 (PARK PRO/XT GL) 63 显存大小: 512 MB of DDR3 SDRAM 64 显卡型号: ATI/AMD Mobility Radeon HD 5450/5470 (PARK PRO/XT GL) [宏碁] 65 显卡BIOS版本: 012.020.000.050.038152 66 频率: 157.0 MHz 67 68 69 存储信息 70 71 存储器1: 72 控制器: Serial ATA 3Gb/s 73 型号: 东芝 MK3265GSX 74 容量: 305,245 MB (320 GB) 75 转速: 5400 RPM 76 缓存: 8192 KB 77 NCQ功能: 支持, Max. Depth: 32 78 S.M.A.R.T.: 存在, 开启 79 48bit LBA: 支持, 开启 80 工作时间: 7088小时测试机配置信息
应该还算可以吧?有点别扭的是在32位系统上硬是要它使用(破解--映射方式)6GBytes的内存,呵呵,会不会有什么后患呢?

之前学习使用的数据库文件多为MDF格式的,直接附加就能使用,但现在这个解压后是.bak格式的,是备份出来的,所以不能以附加的方式进行附加,
而是用【还原】的方式,如图:
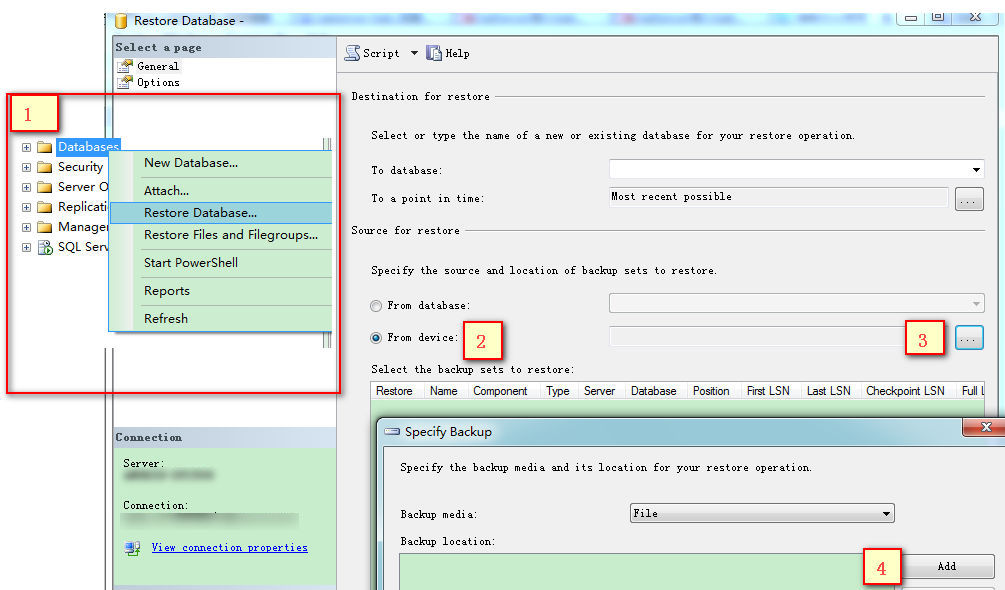
也可以尝试用命令的方式还原bak文件并建立到一个新的数据库,(仅供参考,没实践过)
/* 备份数据DB 到.bak文件。然后利用此bak文件恢复一个新的数据库DBTest。 */ USE master BACKUP DATABASE DB TO DISK = 'g:\DBBack0930.bak' RESTORE FILELISTONLY FROM DISK = 'g:\DBBack0930.bak' RESTORE DATABASE DBTest FROM DISK = 'g:\DBBack0930.bak' WITH MOVE 'DBTest' TO 'E:\Program Files\Microsoft SQL Server2005\Data\DBTest.mdf', MOVE 'DBTest_log' TO 'E:\Program Files\Microsoft SQL Server2005\Data\DBTest_log.ldf' GO
OK!我们就开始还原吧,点击确定之后,我呆住了,机器也似乎呆住了,那还原的状态进度一直(2分钟内)是0,
鼠标光标变成了圆圈忙碌状态,系统瞬间变得很卡,(汗~~在校生,没见过什么大场面,被这还原进度惊呆了,各位不要见笑哦!),
又过了一分钟,终于有反应了,状态的百分比显示20%+,以步进6%左右递增,不会处于“卡死”状态了,
又过了几分钟,终于完成了。以前,课堂练习的附加,还原文件几乎都在秒级完成,几乎没有什么时间等待的概念,
这次可谓见识了什么叫海量(不过,但各位老鸟中,2000w,可能还只是沧海一粟(sù))数据。
还原成功!于是心急着马上查一查心中的她,是否榜上有名了。不加思索,就来了一条SQL语句:
select * from dbo.cdsgus where Name='女神'
噢,又一次惊呆了!在此先省略......字,
慢,别想多了,不是找到了女神的名单,而是电脑再次进入了呆住了的状态,只是查询还在在执行中,一开始,我还以为是内存太小,
CPU太差了,Ctrl+Alt+Del呼唤了任务管理器出来:
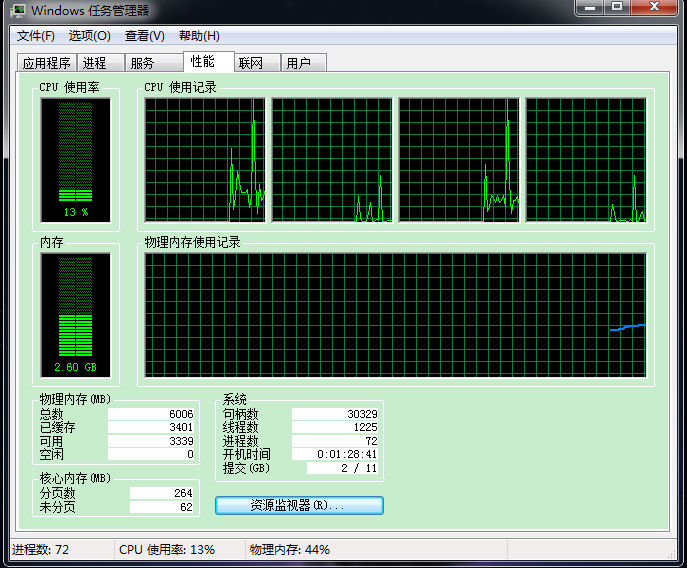
上图告诉我,不是CPU,内存的错,也就在这时,一个闪闪的红星引起了我的注意~~
对,你猜对了!就是硬盘的读写状态提示灯,它在飞快的闪烁,平时,它只会偶尔闪闪。于是,我再次从任务管理中调出【资源监视器】来观察情况,
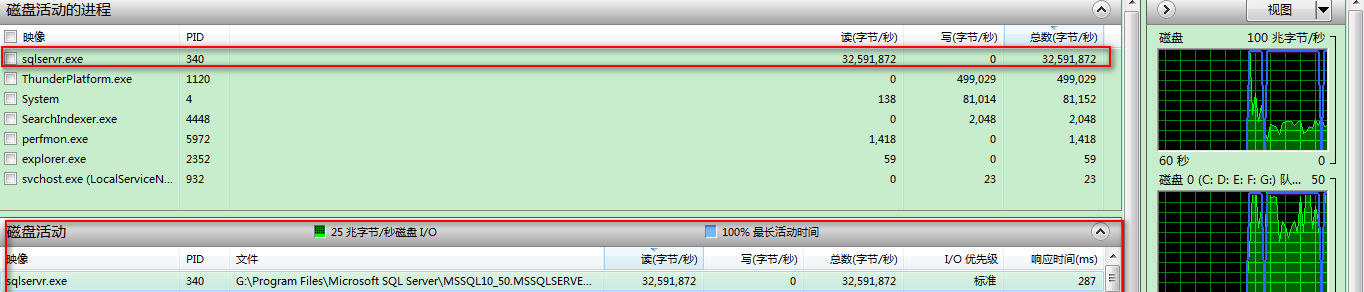
“卡住”的原因找到了,跃然上图,不多说了。以前,很少会关注硬盘IO问题,毕竟经常性地Copy大文件的机会不多。而这次,我才真正关注起硬盘IO问题,在这给自己和各位对IO陌生的朋友补充一下:
读写IO(Read/Write IO)操作
磁盘是用来给我们存取数据用的,因此当说到IO操作的时候,就会存在两种相对应的操作,存数据时候对应的是写IO操作,取数据的时候对应的是是读IO操作。
单个IO操作 当控制磁盘的控制器接到操作系统的读IO操作指令的时候,控制器就会给磁盘发出一个读数据的指令,并同时将要读取的数据块的地址传递给磁盘,
然后磁盘会将读取到的数据传给控制器,并由控制器返回给操作系统,完成一个写IO的操作;
同样的,一个写IO的操作也类似, 控制器接到写的IO操作的指令和要写入的数据,并将其传递给磁盘,磁盘在数据写入完成之后将操作结果传递回控制器,
再由控制器返回给操作系统,完成一个写IO的操作。单个IO操作指的就是完成一个写IO或者是读IO的操作。
对于经常做网络,服务器的来说,I/O不好反映到网站上就是网站页面加载慢、卡、读取数据库慢,
甚至导致网页打开超时显现。
关于IO瓶颈处理的推荐文章:
Understanding Disk I/O - when should you be worried?
http://blog.scoutapp.com/articles/2011/02/10/understanding-disk-i-o-when-should-you-be-worried
贝塔中的DBA » IO系统性能之一:衡量性能的几个指标
http://www.dbabeta.com/2009/io-performence-01_several-concepts.html
等待了200多s,终于有结果了:
![]()
呵呵,终究没有出现女神的名字。
面对这2000w,一条select * from XXX就把我汗颜了,我在想着下一个要查谁的时候,内心一个念头把我拉住了。
不能这样折腾硬盘,伤不起.....
【背景】
平时课堂练习的项目,数量都是几十条为主,也不想无聊去自己建立上万条非真实数据去测试。
【实战】
查询一条数据就要等待200多s,你有这样的时间浪费吗?也就在这时,平时学习的理论知识要派上用场了-----【索引】
【四两拨千斤---索引来支招】
上面提到提到了,执行语句: select * from dbo.cdsgus where Name='女神' 花了200多秒,
假如结果只有一条,各位猜一猜执行:
select top 1 * from dbo.cdsgus where Name='女神' 要花多长时间呢? --留给各位实践一下。
好吧,为了快速地找到那个她,我们为字段名Name建立索引:
Create Index Index_ByName on dbo.cdsgus(Name) --由于记录多,建立索引的时间很慢,耗时:03:49
这时,再去查询执行同样的查询,大家猜一下这一次所花的时间,与刚才的耗时对比,又一次让我惊呆了。
平时课堂练习的项目几乎体会不到索引对于检索速度的影响,这次可谓实践,领会了!
上面注释提到建立索引就花了209秒,那它在背后究竟做了什么呢?建立索引后再次查询,为什么会让我再次惊呆呢?
天下没有免费的午餐,索引能为我们的检索速度起到了四两拨千斤作用,那么,肯定也是要付出代价的。你知道有何代价么?
在课堂中,关于索引的缺点只有理论的提到几句:
第一,创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
第二,索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
第三,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
很少试实践证明,即使实践了,由于是几十,百条数据的项目,感受不到。
这次可谓实践了。
针对以上缺点,
第一条,209s 耗费时间这个深有体会了。
第二条,需要占用物理空间,请看以下数据对比:
未为字段Birthday建立索引前的文件大小: 2013/10/25 00:52 9,379,119,104 shifenzheng.mdf 2013/10/25 00:52 40,239,104 shifenzheng_1.LDF 建立索引后的文件大小: 2013/10/25 10:49 9,994,633,216 shifenzheng.mdf 2013/10/25 00:52 40,239,104 shifenzheng_1.LDF
对于第三条,这里就不实践了,毕竟这个数据库是用来查数据的用的,从第一,二条缺点也可心推断出第三条了。
对于经常用来查询的字段,建立索引的利大于弊,复习一下:
第一,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
第二,可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
第三,可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
第四,在使用分组和排序 子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
第五,通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
有了索引后,我们查询就方便多了,大家想不想知道我们的DuDu是否入围呢? 大伙来围观:
select * from dbo.cdsgus where Name='杜勇' --耗时 4s --(393 row(s) affected)
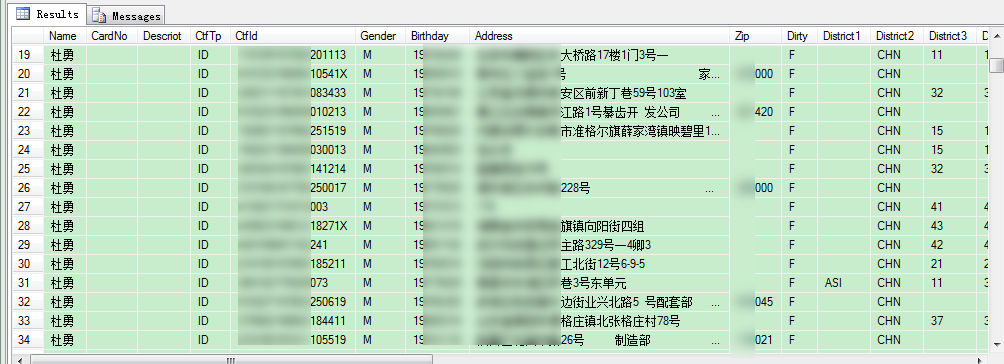
篇幅有限,也防和谐,就不在这公布具体数据,嘻嘻!大家想一想,同名的人在国内还是挺多的嘛!
由于我们在这里都是直接对数据库查询,也就不提供应用层的界面了,如Winform,WebFromt等,如果做那些,
要考虑到储存过程,高效分页查询等,所以下文继续只是用SQL语句演示。
上面从实用主义出发,走的是:下载---》还原---》查询结果,这样的路线,根本没有从底层,结构上的东西去想一想。
嗯,那现们静下心来,看一看这个表设计如何,
Column_name Type Computed Length Prec Scale Nullable TrimTrailingBlanks FixedLenNullInSource Collation Name nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS CardNo nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS Descriot nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS CtfTp nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS CtfId nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS Gender nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS Birthday nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS Address nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS Zip nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS Dirty nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS District1 nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS District2 nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS District3 nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS District4 nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS District5 nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS District6 nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS FirstNm nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS LastNm nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS Duty nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS Mobile nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS Tel nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS Fax nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS EMail nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS Nation nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS Taste nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS Education nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS Company nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS CTel nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS CAddress nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS CZip nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS Family nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS Version nvarchar no 4000 yes (n/a) (n/a) Chinese_PRC_CI_AS id int no 4 10 0 no (n/a) (n/a) NULLView Code
可以看得出作者很懒,除了主键id,其它字段一律用 nvarchar,长度4000应付,其实看到这里的时候,我有点怀疑这些数据的真实性(是否随意生成)的。
nvarchar(n) 变长 处理unicode数据类型(所有的字符使用两个字节表示)
n 的值必须介于 1 与 4,000 之间。字节的存储大小是所输入字符个数的两倍。所输入的数据字符长度可以为零
验证数据真实性(希望更多朋友提供准确的方式)
带着疑问出发,我用了这个语句来查询:
select * from dbo.cdsgus where Address like 'XX省XXx市XX镇XX村%' --X代表地点名称
呵呵,还真找到了几个熟悉的小伙伴,尚且当它是真的吧。又或者原数据库被人加工、整理过之后,随便建立了一个表保存起来的之后再备份出来放在网上的。
(我就纳闷了,整个备份文件还原之后仅只有一个表~)
说回正题,我们再看看:
Name Owner Type Created_datetime cdsgus dbo user table
作者是夜猫子,看一看创建日期:2013-05-23 04:02:21.120。
ID自动增涨列:
Identity Seed Increment Not For Replication id 1 1 0
index_name index_description index_keys Index_Birthday nonclustered located on PRIMARY Birthday Index_ByAddress nonclustered located on PRIMARY Address Index_ByName nonclustered located on PRIMARY Name PK_cdsgus clustered, unique, primary key located on PRIMARY id
原本只有id默认主键索引,Name,Address,Birthday是我后来加上的。
constraint_type constraint_name delete_action update_action status_enabled PRIMARY KEY (clustered) PK_cdsgus (n/a) (n/a) (n/a) (n/a) id
ok!表字段结构我们看完了,尽管这这个数据库只有一个表,表中只设置了一个id主键。但从结果显示中,
我们可以看出,其实有几个字段是作外键使用的,
如下图中的:District1--6,family,id等。
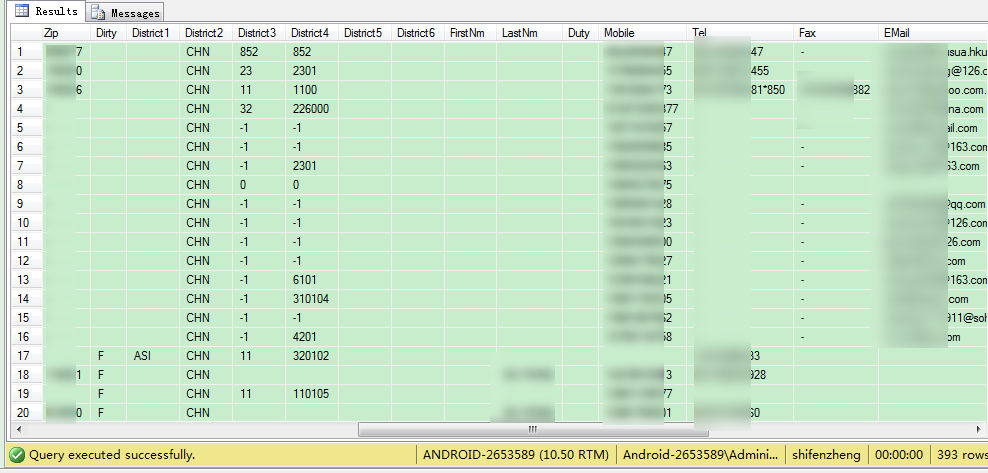
既然了了外键,那么应该还有其它的数据表,希望哪位可以提供上来,呵呵。
数据有了,除了用来练习几个select 语句还能有什么用呢?
这个时候,该发挥我们的天马行空思想了,看一看,想一想里面都有什么了?
由于里面的数据有其真实性,且有了身份证号码,邮箱地址,手机号码......嘿嘿,想到了吧?不要用来做坏事哦!
我们也来学着分析一下,(在园子里的应该都接触过sql语句,下面直接取样分析)
地区分布:(以北,上,广为例)
select count(*) as '北京' from dbo.cdsgus where Address like '北京%' select count(*) as '上海' from dbo.cdsgus where Address like '上海%' select count(*) as '广东' from dbo.cdsgus where Address like '广东%'
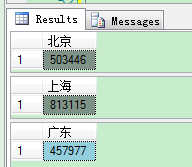
结论:留给大家思考......
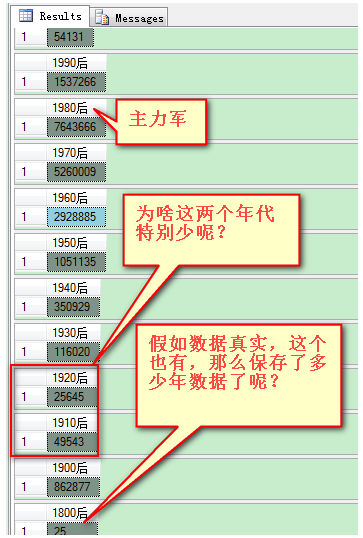
年龄分布:
select count(*) as '00后' from dbo.cdsgus where Birthday like '20%' select count(*) as '1990后' from dbo.cdsgus where Birthday like '199%' select count(*) as '1980后' from dbo.cdsgus where Birthday like '198%' select count(*) as '1970后' from dbo.cdsgus where Birthday like '197%' select count(*) as '1960后' from dbo.cdsgus where Birthday like '196%' select count(*) as '1950后' from dbo.cdsgus where Birthday like '195%' select count(*) as '1940后' from dbo.cdsgus where Birthday like '194%' select count(*) as '1930后' from dbo.cdsgus where Birthday like '193%' select count(*) as '1920后' from dbo.cdsgus where Birthday like '192%' select count(*) as '1910后' from dbo.cdsgus where Birthday like '191%' select count(*) as '1900后' from dbo.cdsgus where Birthday like '190%' select count(*) as '1800后' from dbo.cdsgus where Birthday like '180%'
结果:80后作为主力军,你是否在其中呢?
类似的模糊查询,大家可以灵活变通,如查询客户是移动的用户还是联通的多(根据手机号码前N位),邮箱后缀名等。
建议
查询示例到此告一段落,现在网上也有不少人把这数据库作为数据源,可以通过Web页面进行查询了,
但我用了几个都很不理想,速度慢得可怜,有时候真怀疑他有没有建立相应的索引了,最大的局限性是:仅能通过身份证,姓名去查。
对于作为程序员的你,你接受这样的低权限吗?
所以,建议大家有空还是应该找到这文件,在本地测试,推荐给所有在校生,可以用来练习一下多数据查询,优化问题。
当然,如果哪位朋友有资源的话,建立一个Web页面,可以直接输入sql命令来查询的那就更好了。
最后来一张关于数据价值转化的图:

我们现在得到数据库了,直接到达了加工车间这一层,至于怎样去发掘,那就要看你们的创意了。
自从在学校交了210元的费用考了个所谓的的数据库工程师资格证(学校要求必须要考,但没什么技术含量),
之后比较少接触SqlServer数据库了,转眼,10月底了,再过一段时间就要准备实习了,目前还是在校生。
这次藉由这个2000w来温习了一下相关的基础知识,
磁盘IO性能问题,数据备份,恢复,索引,模糊查询,函数调用,大数据分析,挖掘,利用等。
此文,仅仅代表一个在校生初试2000w条记录的数据库的浅显实践,泛泛而谈,个中的结论,推断难免轻浮、果断。
不足之处,还望各位资深读者多多指导,斧正本文的错误论点。
如果本文吸引了你,为你带来了灵感,帮助,麻烦你轻轻点击【推荐】,
你的热心评论,推荐,是我分享文章的强大动力。谢谢阅读!