最近网上盛传两千万酒店用户数据泄漏,出于好奇,我也从网上下载了一份下来。本次下载纯粹是出于学习和研究用,不会做什么坏事,不要问本人要下载地址,大家自己找。由于本人并不是学统计和数据挖掘方面的,所以只能浅显的做做统计分析,下面开始我们的学习和研究。
首先,数据源只有一个表(总数据2005W),里面主要存放了用户的姓名、证件类型,证件号码,生日,性别,住址,手机号码,邮箱等私人信息。这些数据应该是从多个数据源集成进来的,因为里面的格式很不工整,有些默认值使用的也不一样。我们要做数据分析,那么需要进行数据清理,然后建立Cube,使用ETL转换成维度模型,最后使用各种前段呈现工具进行展示。
主要是去除字符串首尾的空格,还有就是很多数据是没有生日和性别的值的,但是我们知道,通过身份证号码就能够推断出生日和性别,所以这部分数据可以补齐。另外还有就是数据重复问题,我们可以把身份证号码作为主键进行去重,我搜索了下,有相同身份证号码的大概占总数据的0.5%,所以我也就没有做去重工作,认为里面的数据都表示一个独立的人。
有姓名,我们可以对姓氏分布进行分析,有了身份证号码,我们可以对出生地(省、市、区)进行分析,对出生的年月分布进行分析,对性别分布进行分析。住址由于格式太不一样,就不分析了,有了手机号码我们可以对手机号码段的分布进行分析,也可以对用户所在地进行分析(绝大多数用户使用的手机号就是平时生活所在地的号),有了邮箱地址可以对域名进行统计。
要得到身份证对于的地区,以及电话号码对应的地区,可以从网上找到对应表,导入数据库中即可进行联合分析。

在建立了多维模型后,使用Excel连接Cube进行多维分析是个很简单的事情。下面我们看看所有人员的年龄分布。

我们可以看到,住酒店的人主要集中在1962~1990年左右,由于我们的数据是Budget Hotel(比较廉价的酒店)数据,可以想象,住这些酒店的都是社会的中低层,高富帅和官二代是肯定不住这种酒店的,穷的很的那就只有住更廉价的招待所或者睡火车站了。住酒店的人的年龄段大部分都还在工作,看来很多人住酒店还是因为商务的原因。从16岁到20岁左右的酒店人数还是少数哈,并不是传说的都是约炮数据。
下面再来对比一下各年龄段性别上的分布。(为了便于观看主体数据,我把时间段缩短成1949~2000)

从图中可以看到,在1990年之前出生人里面,住酒店的男性比例远高于女性,毕竟出差的人还是以男性居多吧,这个数据可以理解。但是在90后的年龄段里面,女性比例和男性比例基本是1:1,甚至还有些数据是女性比例高于男性,90后才刚跨入社会开始工作,或者还没有开始工作,所以不存在大量男性出差的问题,但是为什么女性比例会比男性比例高呢?这个问题有意思,留给大家自己YY。
我们可以从身份证号码前2位知道一个人在出生上户口的时候所在的省份,可以统计每个省份的住酒店人数。本身统计这个没什么意思,把全国人口统计数据拿出来比较就比较有意思了。下面看看做出的表。
省份 酒店排行 人口排行 上升名次 江苏 1 5 4 山东 2 2 0 浙江 3 10 7 河南 4 3 -1 安徽 5 8 3 湖北 6 9 3 上海 7 24 17 河北 8 6 -2 辽宁 9 14 5 山西 10 18 8 四川 11 4 -7 江西 12 13 1 黑龙 13 15 2 陕西 14 16 2 福建 15 17 2 湖南 16 7 -9 广东 17 1 -16 北京 18 26 8 吉林 19 21 2 内蒙 20 23 3 天津 21 27 6 甘肃 22 22 0 广西 23 11 -12 贵州 24 19 -5 新疆 25 25 0 云南 26 12 -14 青海 27 30 3 宁夏 28 29 1 重庆 29 20 -9 海南 30 28 -2 西藏 31 31 0我们可以看到,上海、浙江、山西、北京、天津这几个地方的住酒店人数排名远高于人口排名,江浙一带和京津塘一带经济很发达,出差频繁,可以理解,但是山西为什么出差那么多呢?可能山西人有商业的基因吧。
另外就是发现广东、广西、云南、四川、重庆的住酒店人数小于人口排名,广东很发达啊,怎么会住酒店的人少呢?可能是因为广东人喜欢在本地发展吧,出来到处漂的并不多。
上面只是从身份证上得出的省份,下面再看看手机号得出的省份数据,这个数据反映的应该是人们当前工作/生活的省份的情况。
省份 酒店排行 人口排行 上升名次 江苏 1 5 4 上海 2 24 22 北京 3 26 23 山东 4 2 -2 广东 5 1 -4 浙江 6 10 4 河南 7 3 -4 湖北 8 9 1 辽宁 9 14 5 陕西 10 16 6 河北 11 6 -5 福建 12 17 5 山西 13 18 5 安徽 14 8 -6 黑龙 15 15 0 天津 16 27 11 四川 17 4 -13 江西 18 13 -5 湖南 19 7 -12 吉林 20 21 1 内蒙 21 23 2 重庆 22 20 -2 广西 23 11 -12 甘肃 24 22 -2 贵州 25 19 -6 新疆 26 25 -1 云南 27 12 -15 海南 28 28 0 宁夏 29 29 0 青海 30 30 0 西藏 31 31 0
这个数据比上一个数据的差别更大,可以说是非常不平衡,可以看到,上海、北京、天津的商业很发达,人口排名不高,但是住酒店的人口排名非常高。比较杯具的是云南、四川、湖南、广西,工作和出差人数远少于人口基数。
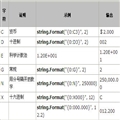
这里我只统计了姓,没有统计名,不过姓名可以先说一下,在所有姓名数据中,重名最高的前10个姓名是:张伟,王伟,王磊,李伟,张磊,刘伟,李强,张勇,王勇,刘洋。相信很多人周围就有这些姓名的人。重名排行前250位左右的都是两个字的姓名,看来起三个字姓名的重名率会低很多很多。重名率最高的Top10三个字姓名的是:王建军,王志强,王建华,王晓东,张建军,王婷婷,王志刚,张建华,张志强,张婷婷。好像周围也很容易找到这些姓名的人。
下面还是说姓吧,这个对中国人来说很重要。姓氏很多,网上找了一个前200姓氏人口排名表,拿来和我做出来的数据对比,发现有以下几个数字比较突出:
其中原因还得从其他维度去联合分析,可能是因为有些姓是集中在某个地方吧!
另外一个题外话,在Top200的姓氏人口统计中没有肖姓,却有萧姓,其实这是同一个姓,古时候根本没有姓肖的,后来由于文革时期的简体字运动,把萧简写成了肖,后来这个简写又被取消了。
很简单的一个统计分析,看看一年12个月里面,哪个月出生的人最多。

从图中可以看出,10月份的人最多,4月份的人最少。为什么会这样呢?可能需要专家来解释。
我这里取的是手机号码的前三位,应该哪个最高?我一直以为是138,结果发现是139。
139 1399857 138 1230530 135 782764 136 778188 137 683742 186 581451 159 456526 158 434760 133 356135 150 324798移动的号码占很大优势,联通186和电信的133都排在后面了。看来广大中低产阶级还是选移动的多啊。
本来还可以进一步分析具体是全球通、神州行还是动感地带的,难得提取了。有需要的话可以再花点时间分析分析。
邮箱域名里面,哪个最多?以前听说是163,后来又听说QQ邮箱把他超越了,我们还是看数据吧。
前10大邮箱域名排名:
@qq.com 611842 @163.com 594392 @126.com 274512 @hotmail.com 203237 @sina.com 151798 @yahoo.com.cn 101692 @gmail.com 96346 @139.com 67565 @sohu.com 50179 @yahoo.cn 31274QQ邮箱果然是最多的,不过优势也不是那么明显,而且排第二第三的都是网易的邮箱,加起来就超过QQ邮箱了。
以上只是简单的分析,其实在进行了很好的数据清洗和模型设计后,我们还可以从中挖掘出很多好玩的地方。尤其是应用上数据挖掘算法,可以造成多个维度之间的相关性,由于工作较忙,时间比较仓促,所以实验就做到这里。大家有什么想分析的话可以留言,我再做做。